Ollama and Web-LLM: Building Your Own Local AI Search Assistant


Web-LLM is an open-source, Python-based web-assisted Large Language Model (LLM) search assistant available under the MIT license. It is freely accessible to users and the community. You can ask a question, and the system will search the web for recent, relevant information. It reviews the top results, refines the searches if needed, and gathers sufficient details to answer your query. If it cannot fully answer after five searches, it provides the best possible response based on the information gathered.
The tool processes locally, conducts private DuckDuckGo searches, refines results dynamically, and ensures relevance through multiple attempts. It offers vibrant visuals and combines insights for thorough responses.
Prerequisites
- GPUs: 1xRTXA6000 (for smooth execution).
- Disk Space: 100GB free.
- RAM: 48 GB.
- CPU: 48 Cores
Step-by-Step Process to Setup Web-LLM-Assistant-Llamacpp-Ollama
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meets GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you've signed up, log into your account.
Follow the account setup process and provide the necessary details and information.
Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift's GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.
Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deployment.
Step 3: Select a Model, Region, and Storage
In the "GPU Nodes" tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.
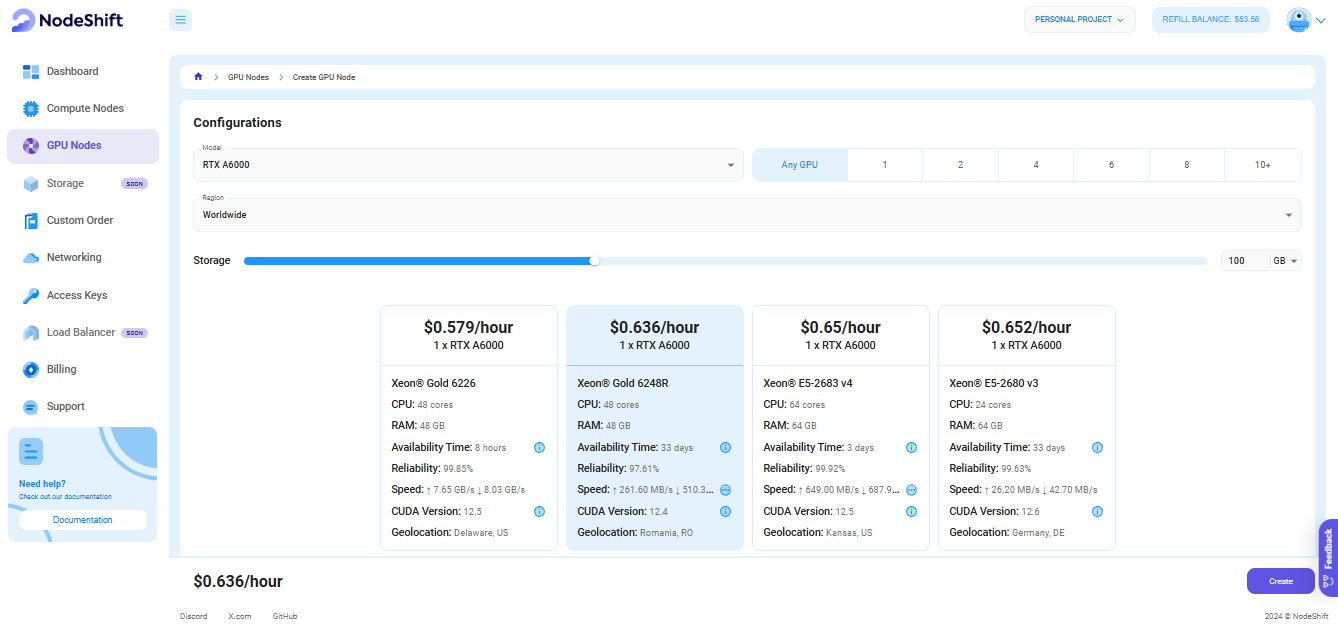
We will use 1x RTX A6000 GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy Web-LLM-Assistant-Llamacpp-Ollama on an NVIDIA Cuda Virtual Machine. This proprietary, closed-source parallel computing platform will allow you to install Web-LLM-Assistant-Llamacpp-Ollama on your GPU Node.
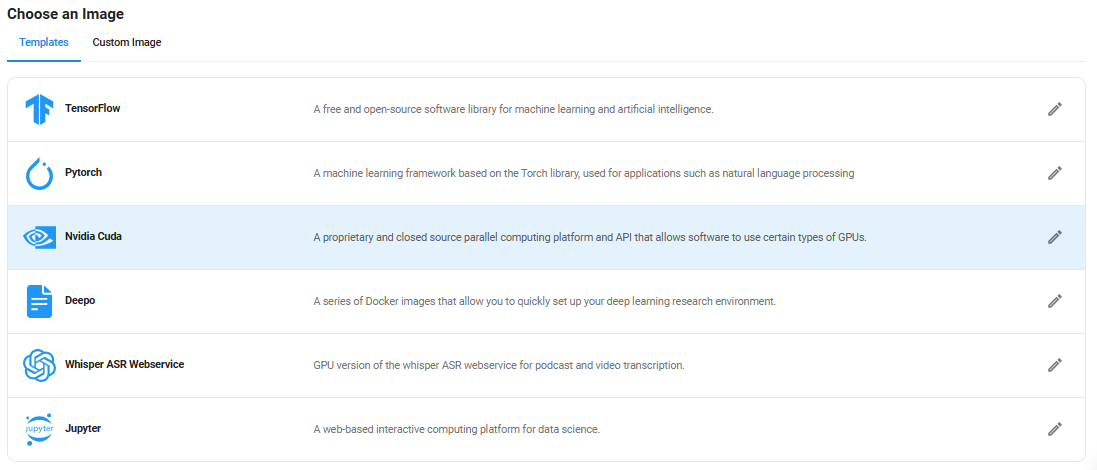
After choosing the image, click the 'Create' button, and your Virtual Machine will be deployed.
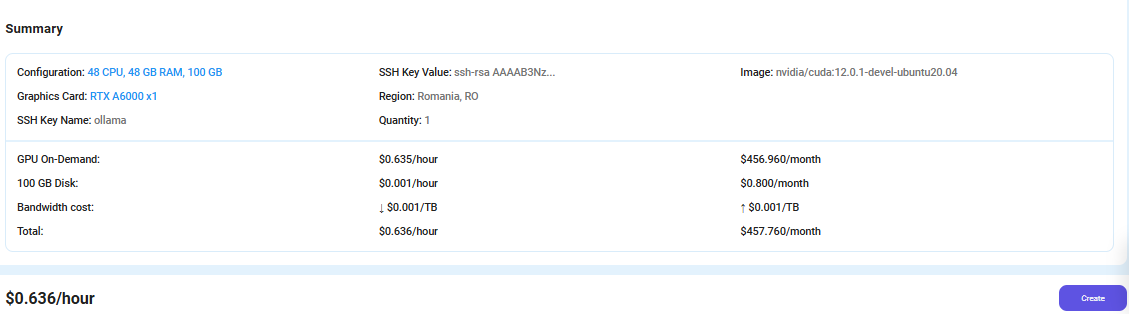
Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.
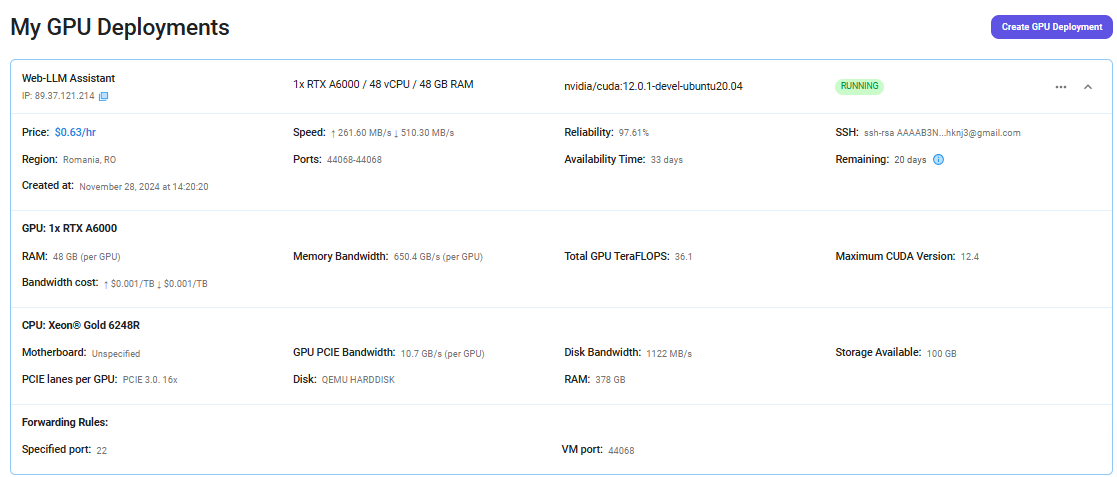
Step 7: Connect to GPUs using SSH
NodeShift GPUs can be connected to and controlled through a terminal using the SSH key provided during GPU creation.
Once your GPU Node deployment is successfully created and has reached the 'RUNNING' status, you can navigate to the page of your GPU Deployment Instance. Then, click the 'Connect' button in the top right corner.
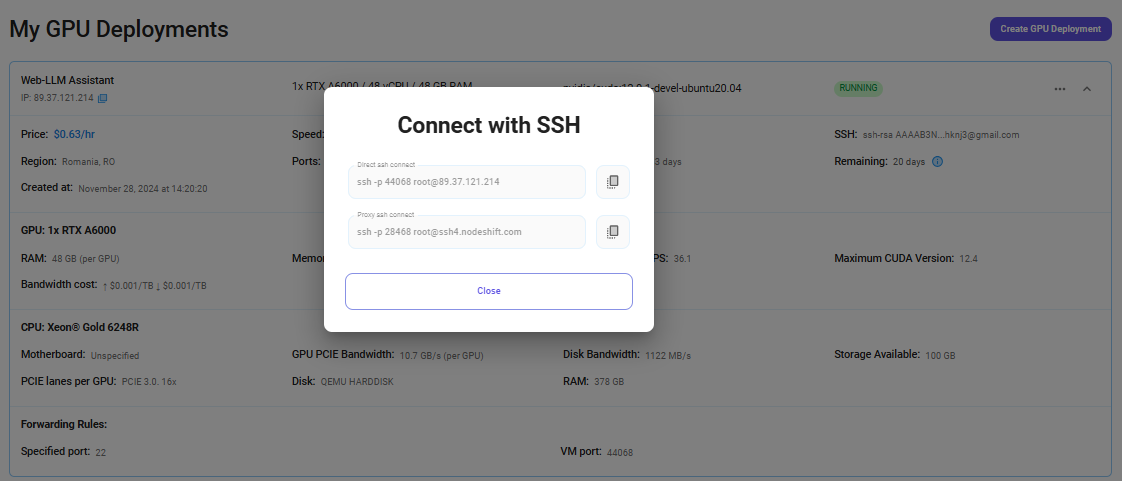
Now open your terminal and paste the proxy SSH IP or direct SSH IP.
Next, if you want to check the GPU details, run the command below:
nvidia-smi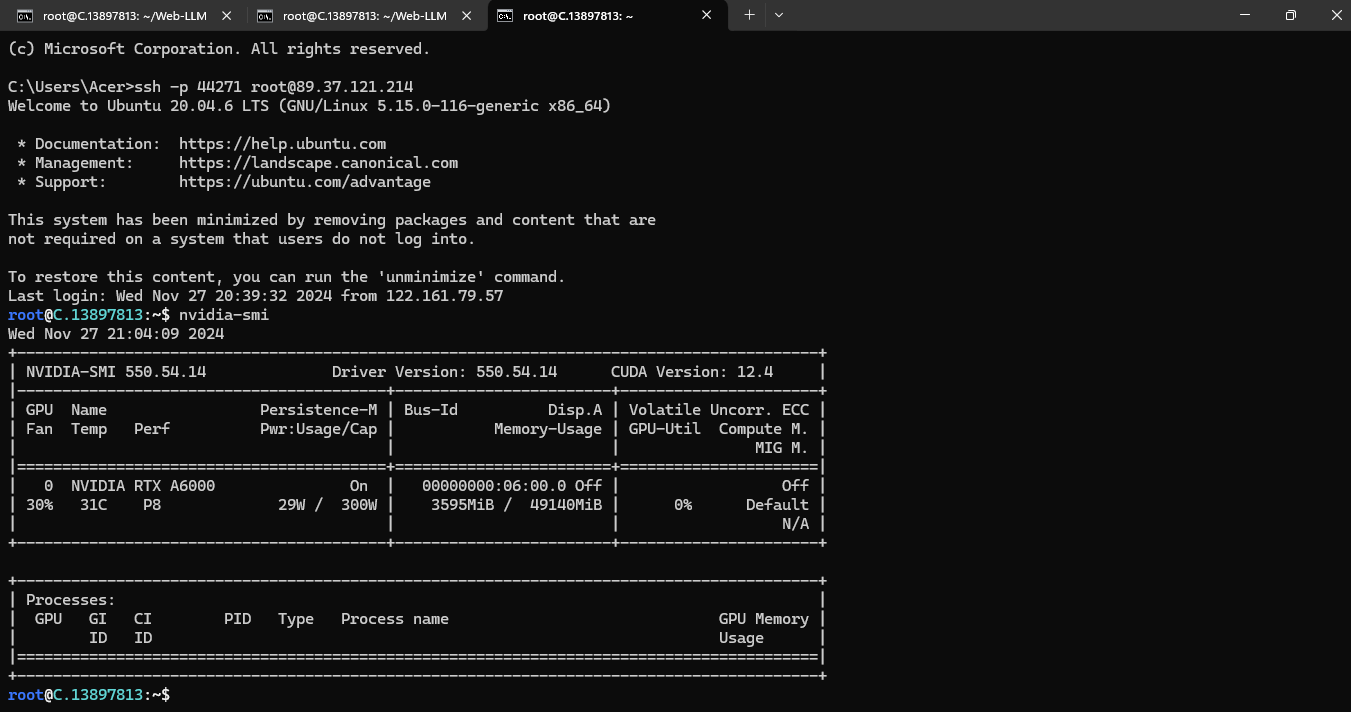
Step 8: Clone the Repository
Run the following command to clone the Web-LLM-Assistant-Llamacpp-Ollama repository:
https://github.com/TheBlewish/Web-LLM-Assistant-Llamacpp-Ollama.git
cd Web-LLM-Assistant-Llamacpp-Ollama
Step 9: Check the Available Python version and Install the new version
Run the following command to check the available Python version:
apt update
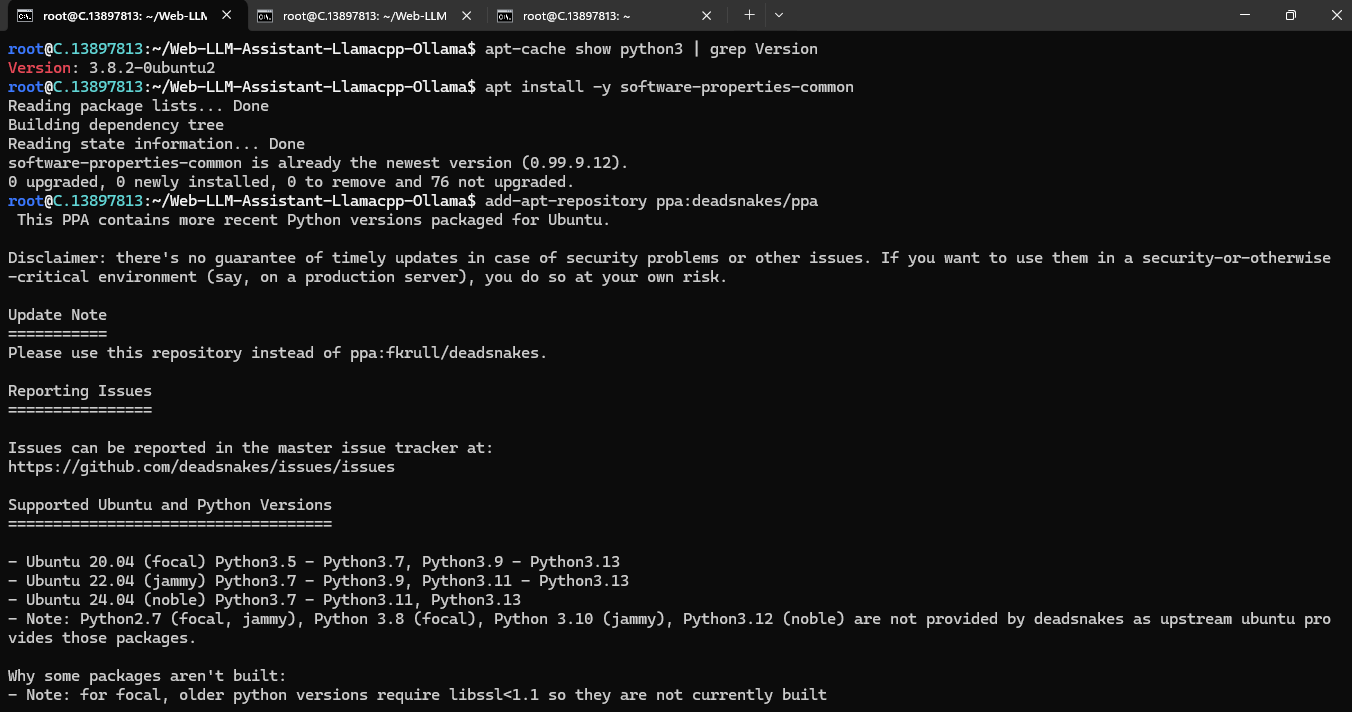
apt-cache show python3 | grep Version
If you check the version of the python, system has Python 3.8.2 available by default. To install a higher version of Python, you'll need to use the deadsnakes PPA.
Run the following command to add the deadsnakes PPA:
apt install -y software-properties-common
add-apt-repository ppa:deadsnakes/ppa
apt update
The deadsnakes PPA provides newer versions of Python for Ubuntu. Add it to your system:
Step 10: Install Python 3.11
Now, run the following command to install Python 3.11 or another desired version:
apt install -y python3.11 python3.11-venv python3.11-dev python3-pip
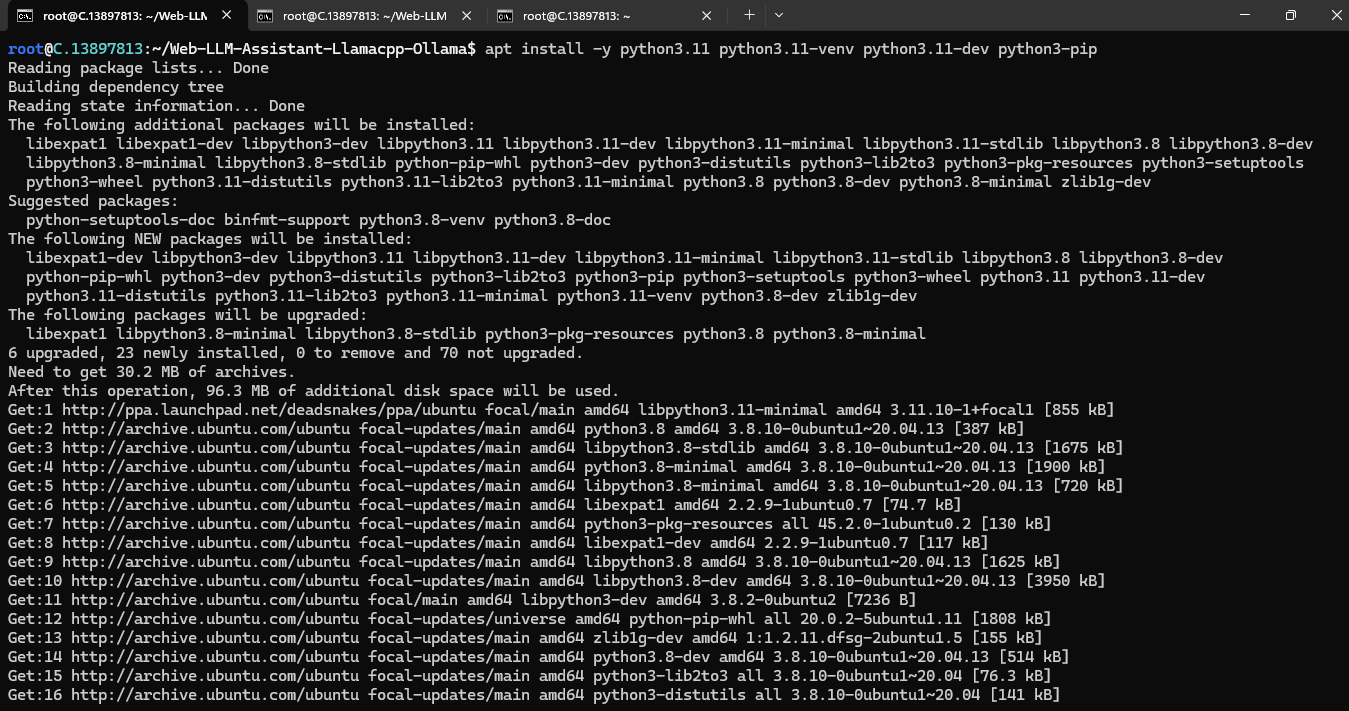
Then, run the following command to check the installed version:
python3.11 --version

Step 11: Install python3.11-venv
Run the following command to install the venv module for Python 3.11:
apt install -y python3.11-venv
Then, run the following command to create the virtual environment:
python3.11 -m venv venv
Next, run the following command to activate the virtual environment:
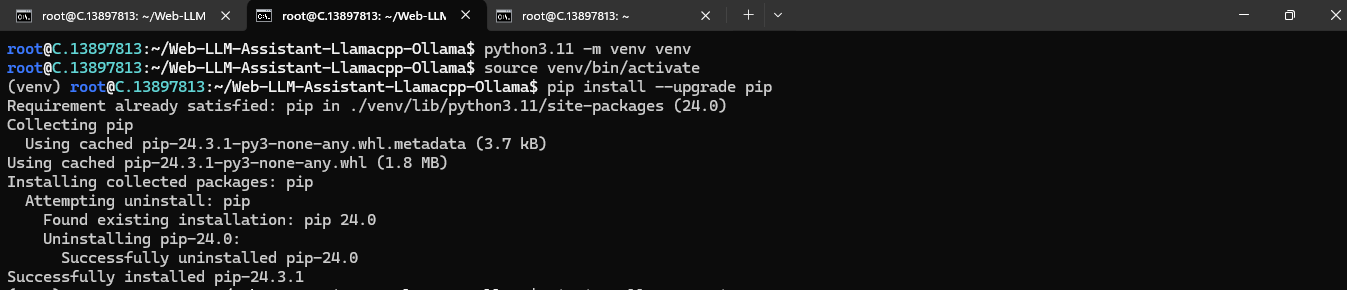
source venv/bin/activate
Last, run the following to upgrade pip in the virtual environment:
pip install --upgrade pip
Step 12: Install the project dependencies
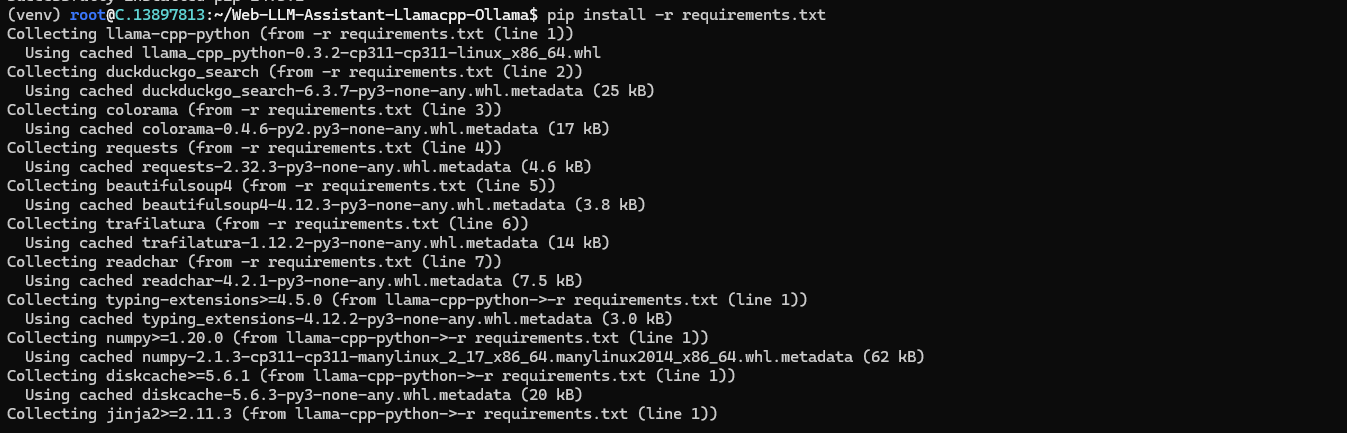
Run the following command to install the project dependencies:
pip install -r requirements.txt
Step 13: Install Ollama
After completing the steps above, it's time to download Ollama from the Ollama website.
Website Link: https://ollama.com/download/linux
Run the following command to install the Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Step 14: Serve Ollama
Run the following command to serve or host the Ollama:
ollama serve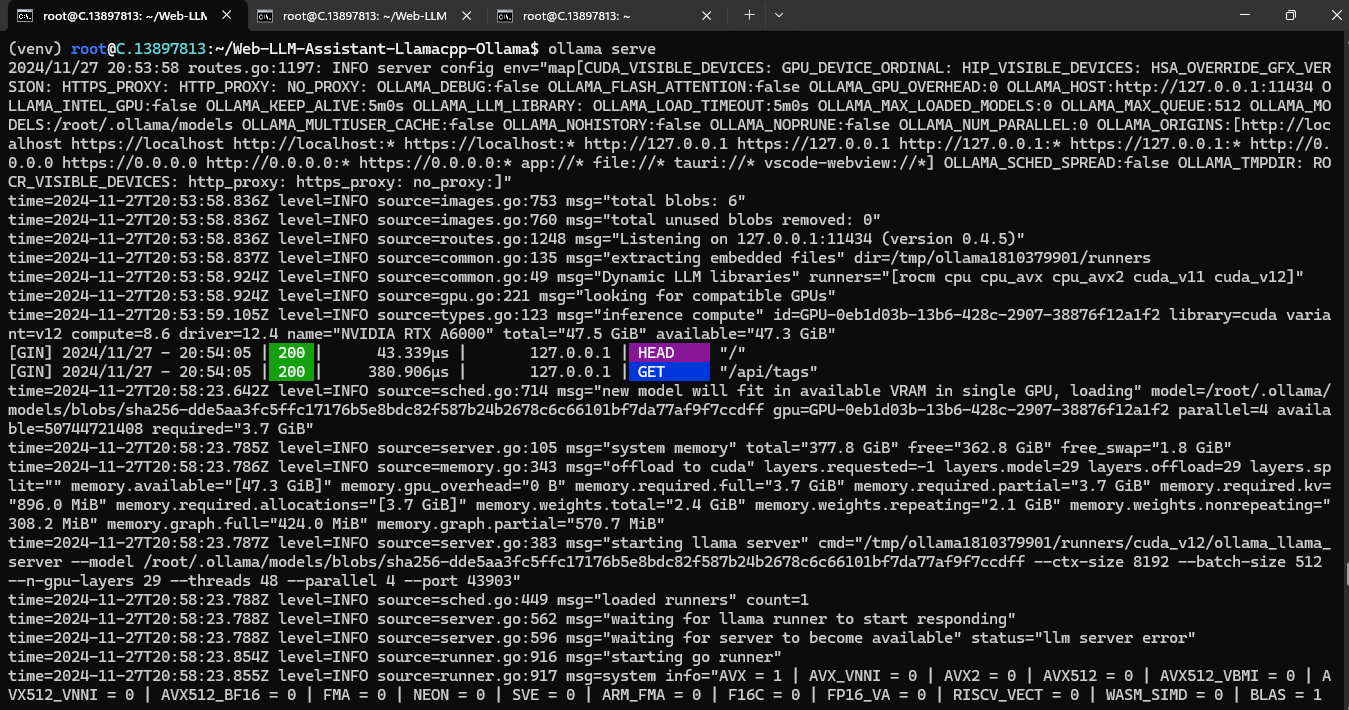
After completing the steps above, now your project, repository, packages, dependencies and Ollama are setup.
Step 15: Pull any Model from Ollama
Open a new terminal and use SSH command to connect with VM again.
We will use llama 3.2 from the Ollama website:
Link: https://ollama.com/library/llama3.2
To pull the llama 3.2 model, run the following command:
ollama run llama3.2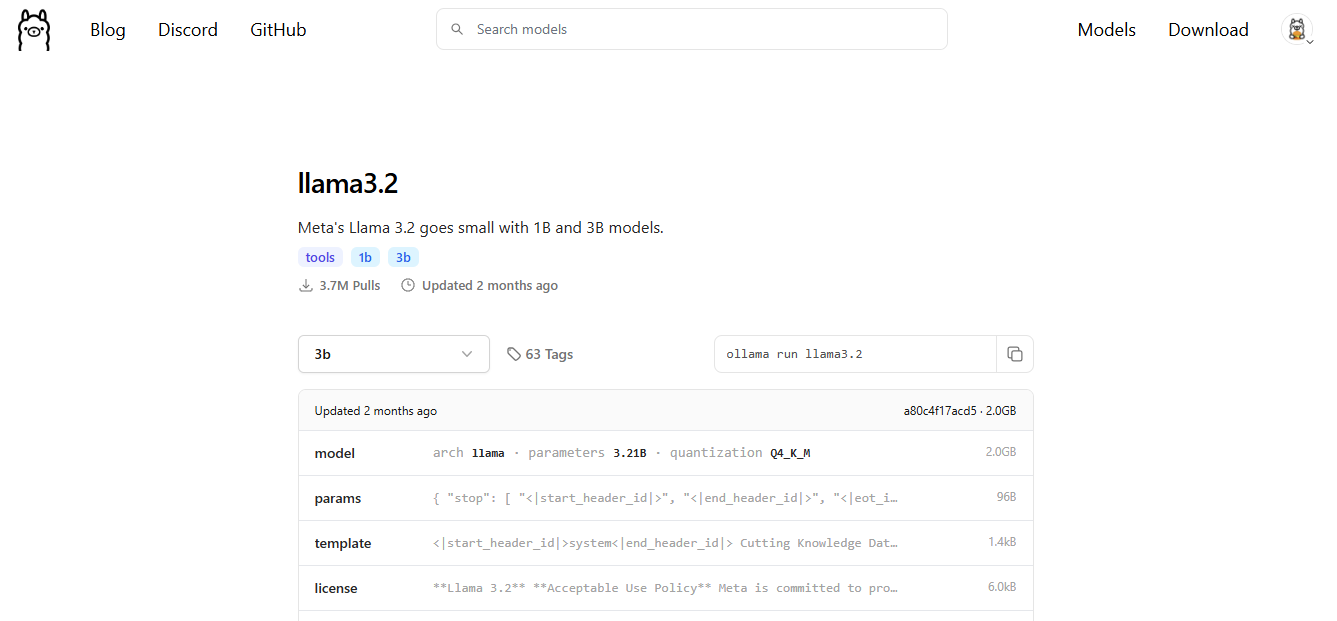
Then, after pulling run the following command to check the model is available or not:
ollama list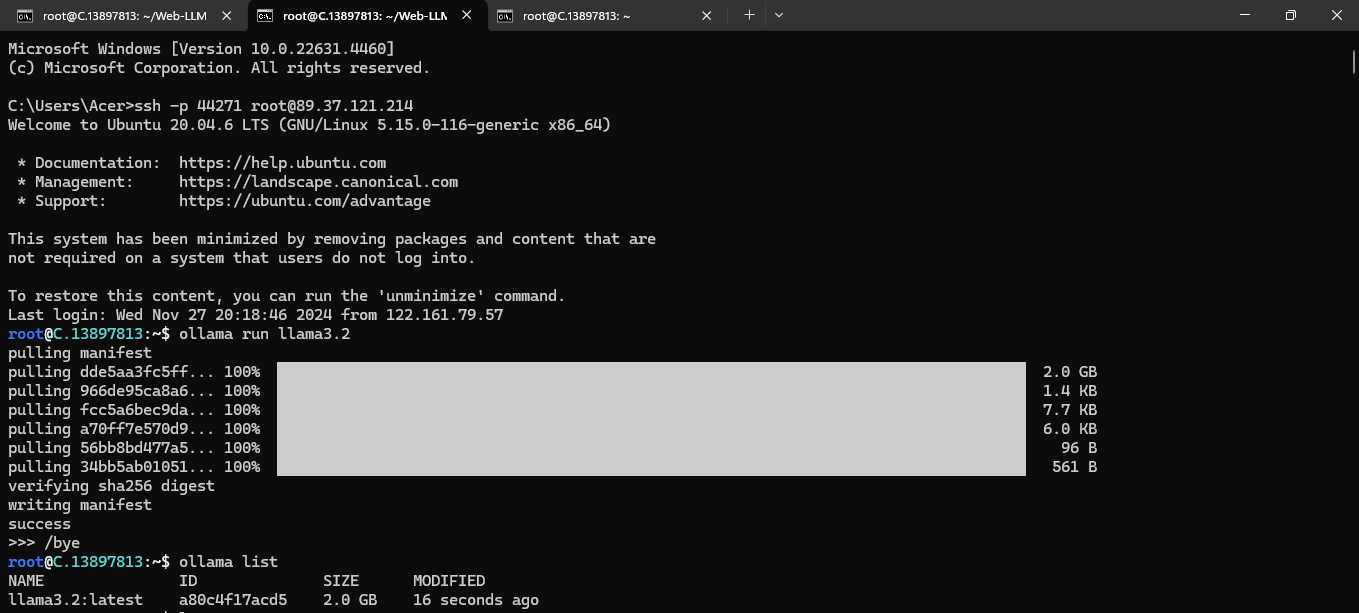
Step 16: Update the System and Install Vim
What is Vim?
Vim is a text editor. The last line of the text editor is used to give commands to vi and provide you with information.
Note: If an error occurs stating that Vim is not a recognized internal or external command, install Vim using the steps below.
Step 1: Update the package list
Before installing any software, we will update the package list using the following command in your terminal:
sudo apt update
Step 2: Install Vim
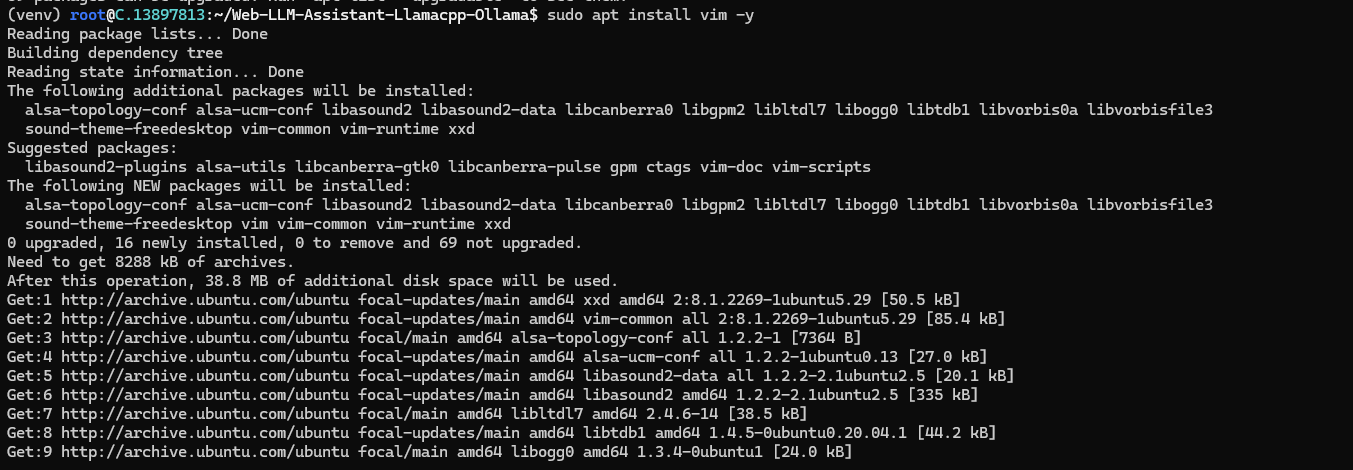
To install Vim, enter the following command:
sudo apt install vim -y
This command will retrieve and install Vim and its necessary components.
Step 17: Edit the LLM Configuration File
Run the following command to access the LLM configuration file:
vim llm_config.pyYou can see that in the configuration file, Ollama is already set up, and you only need to enter the model name you want to use. Here, we use Llama 3.2.
If you prefer to use Llama CPP, you can proceed with that as well.
Entering the editing mode in Vi:
Follow the below steps to enter the editing mode in Vim
Step 1: Open a File in Vim
Step 2: Navigate to Command Mode
When you open a file in Vim, you start in the command mode. You can issue commands to navigate, save, and manipulate text in this mode. To ensure you are in command mode, press the Esc key. This step is crucial because you cannot edit the text in other modes.
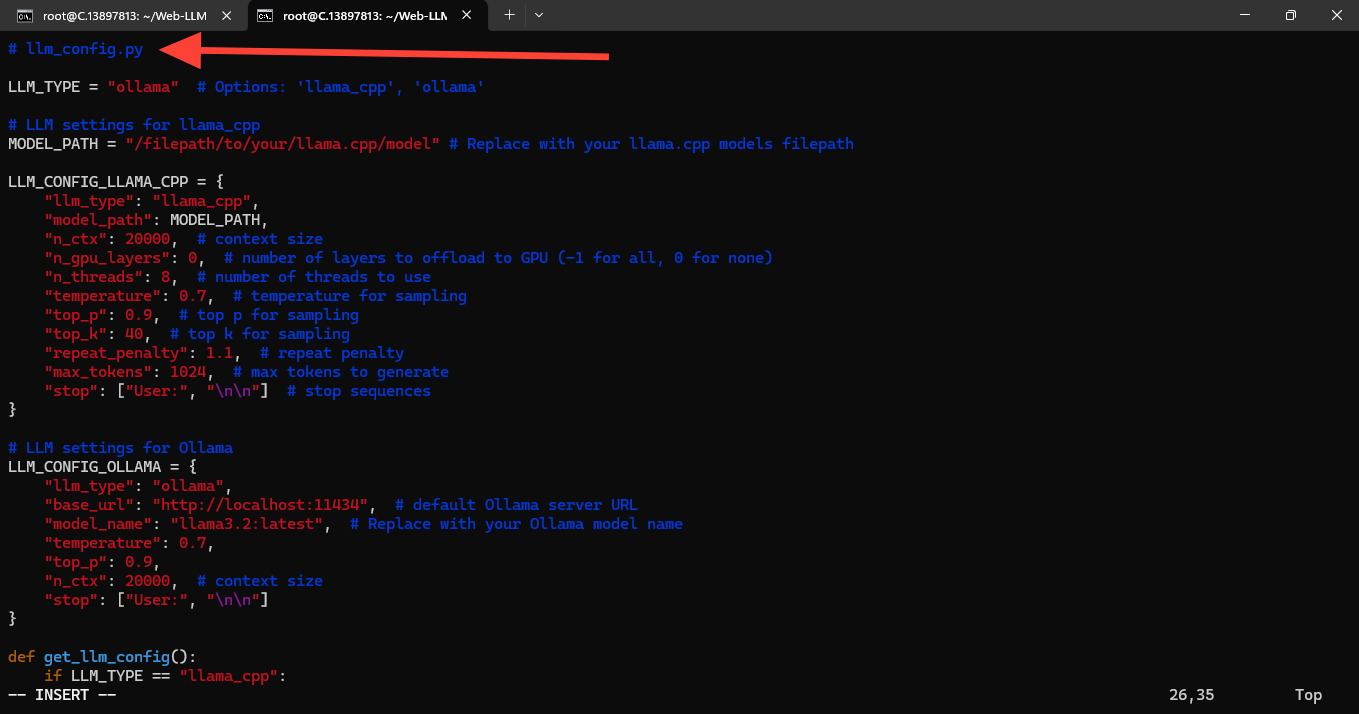
Then, in editing mode, open the configuration file, check the LLM settings for the Ollama option, and add the model name you are using (e.g., Llama 3.2).
Save and close the file (Ctrl+X, Y, Enter).
Step 18: Run the Web-LLM-Assistant-Llamacpp-Ollama Tool
Now, execute the following command to run the Web-LLM-Assistant-Llamacpp-Ollama tool:
python Web-LLM.py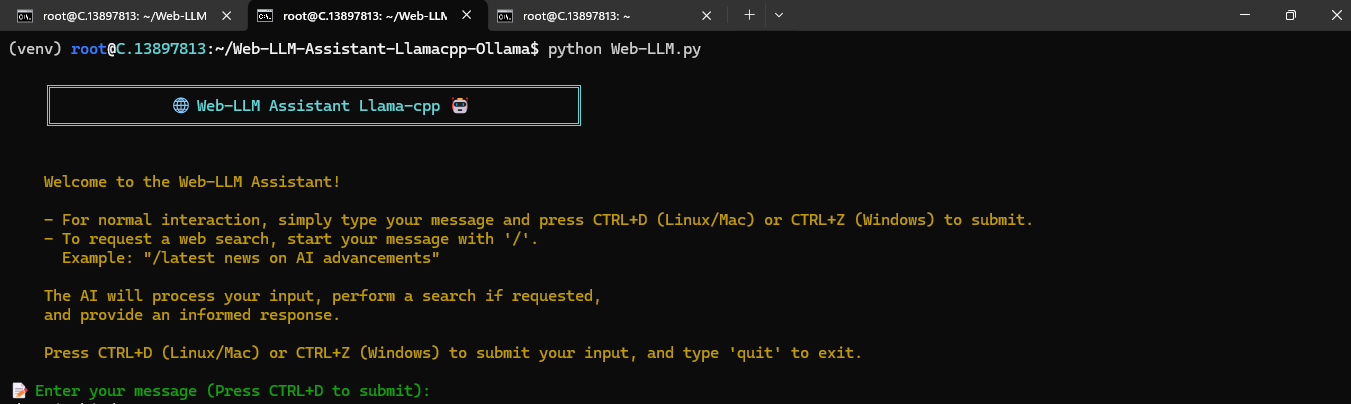
Step 19: Enter your Message or Question
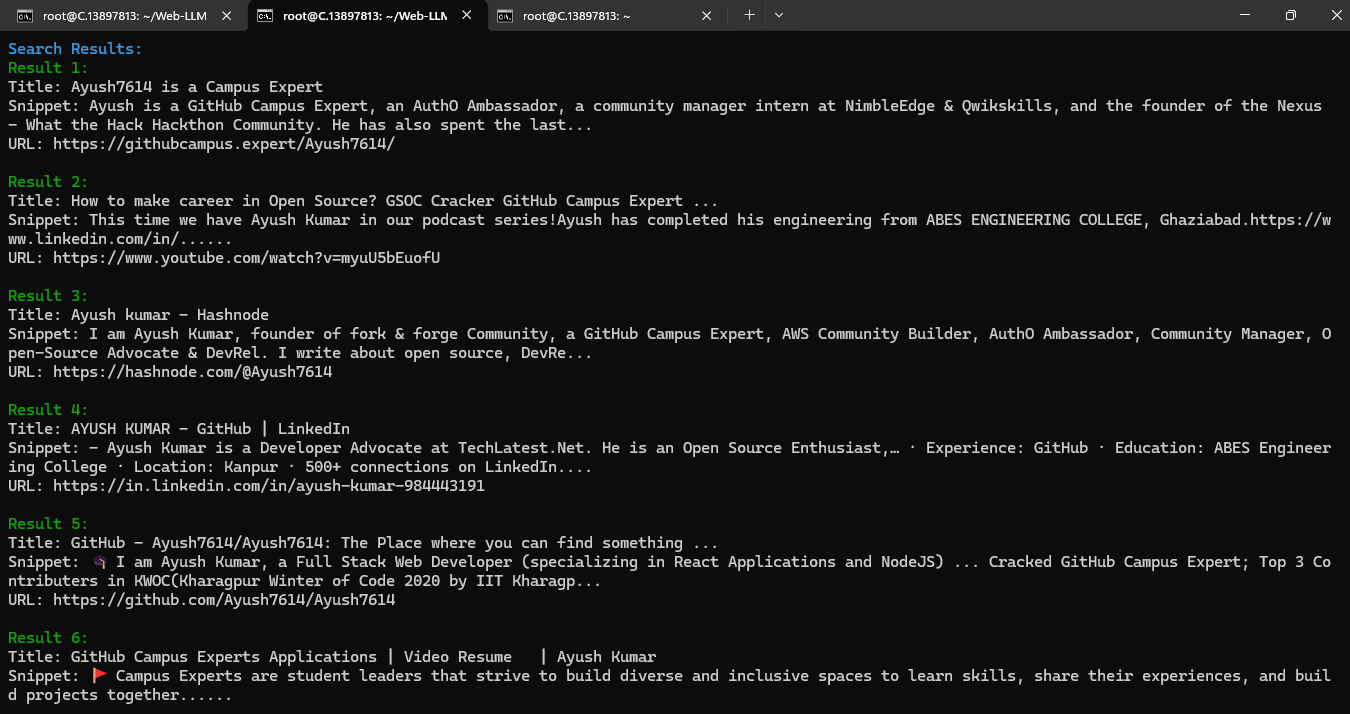
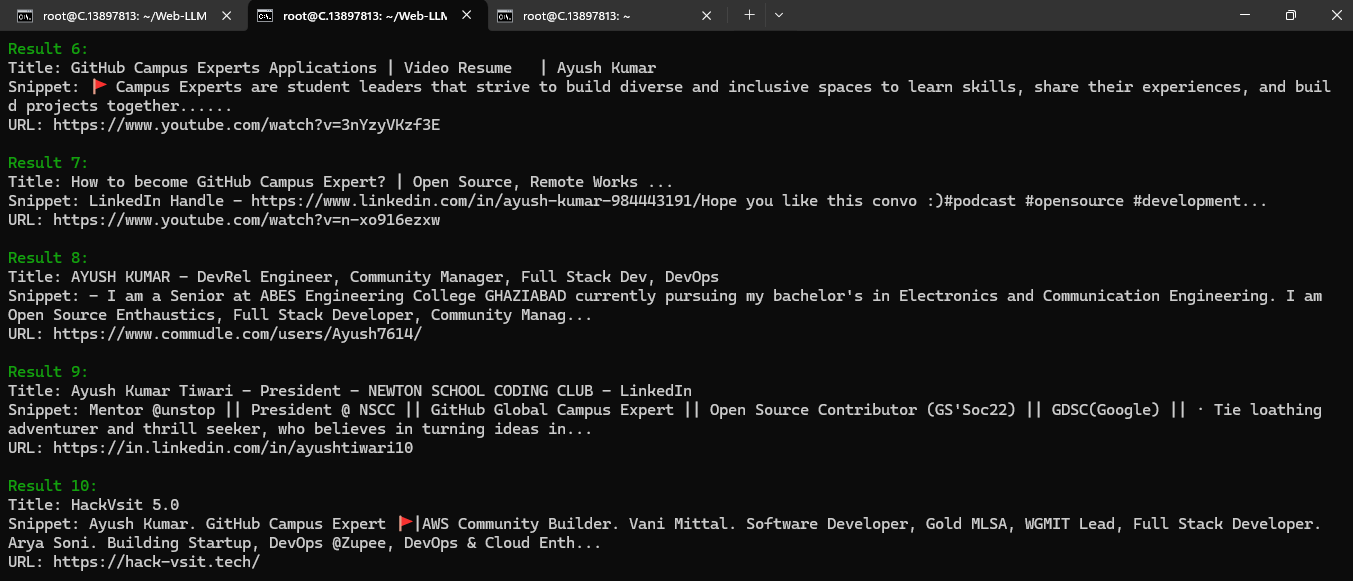
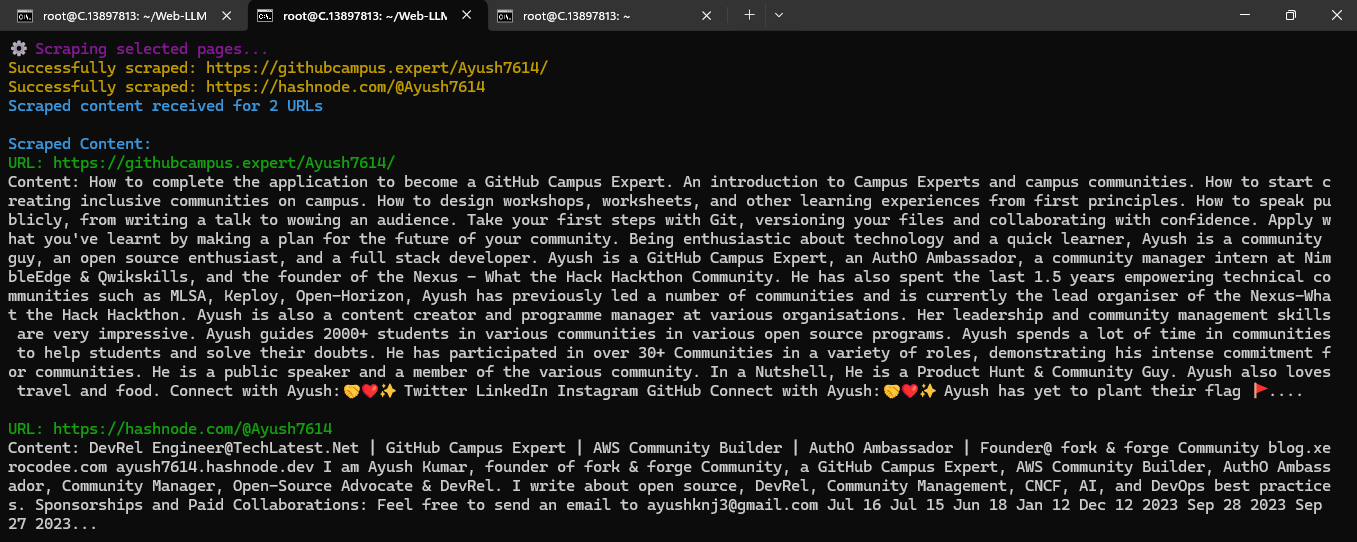
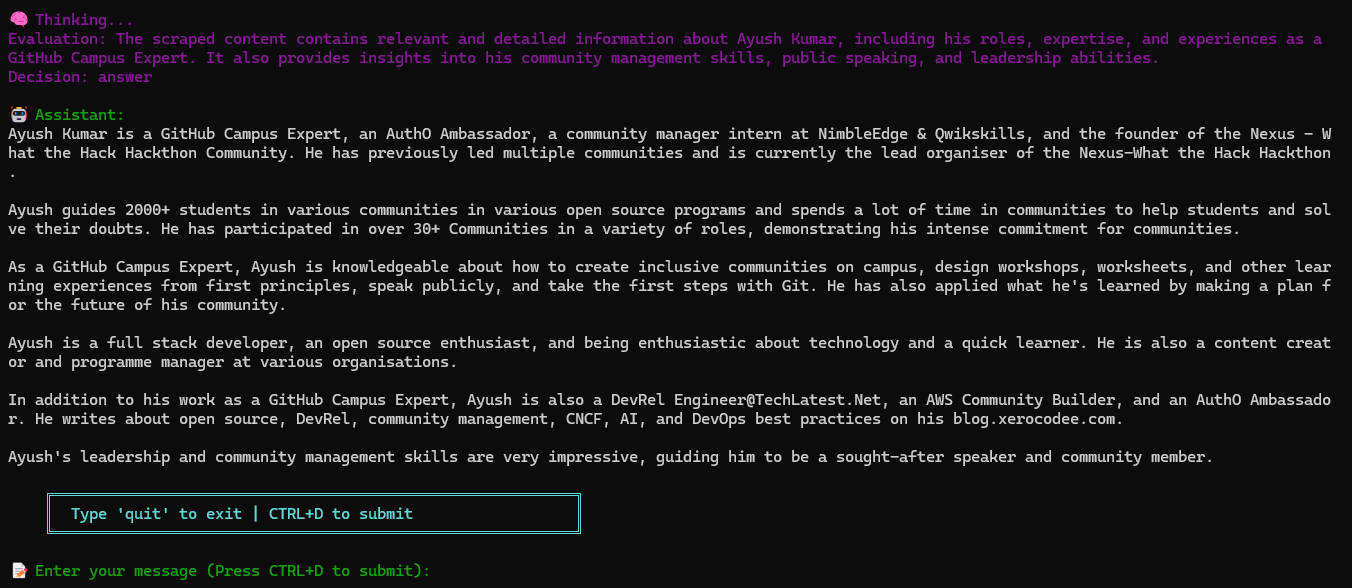
Now enter your message or ask question from assistant. And then press CTRL+D to submit your message or question.
Example 1:
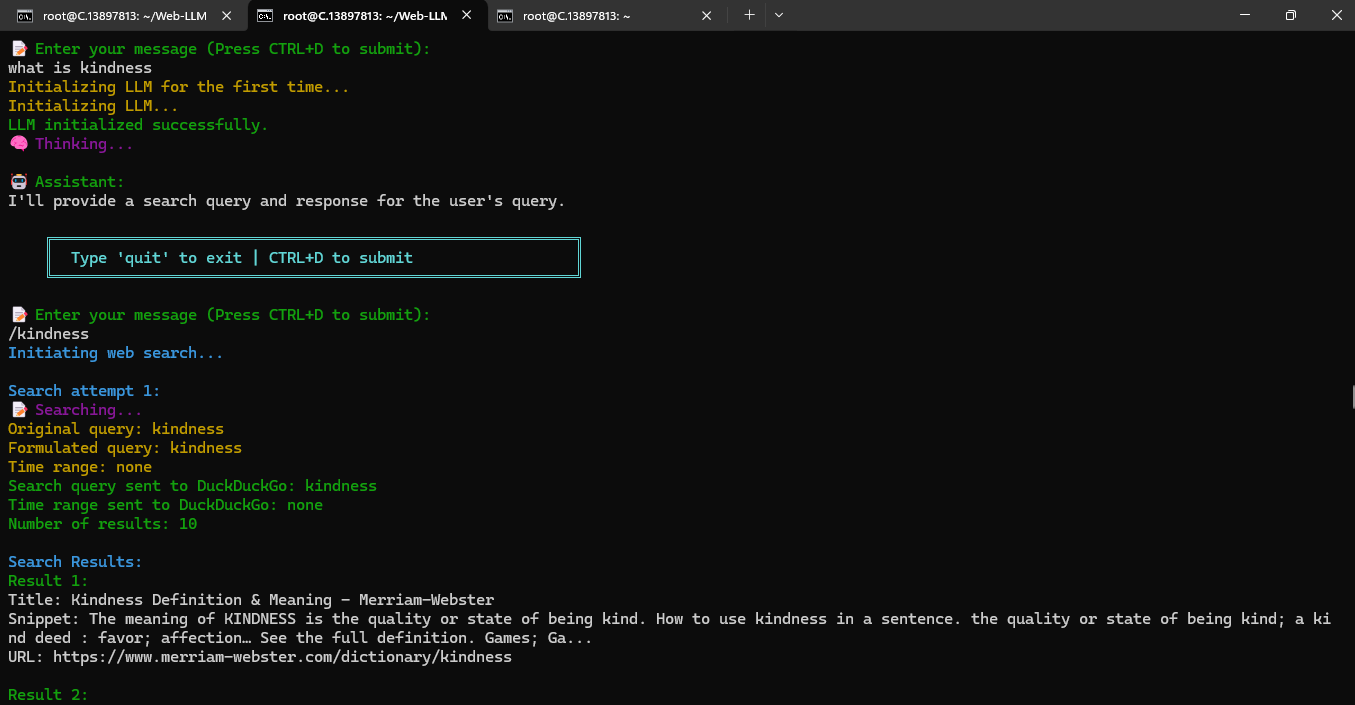
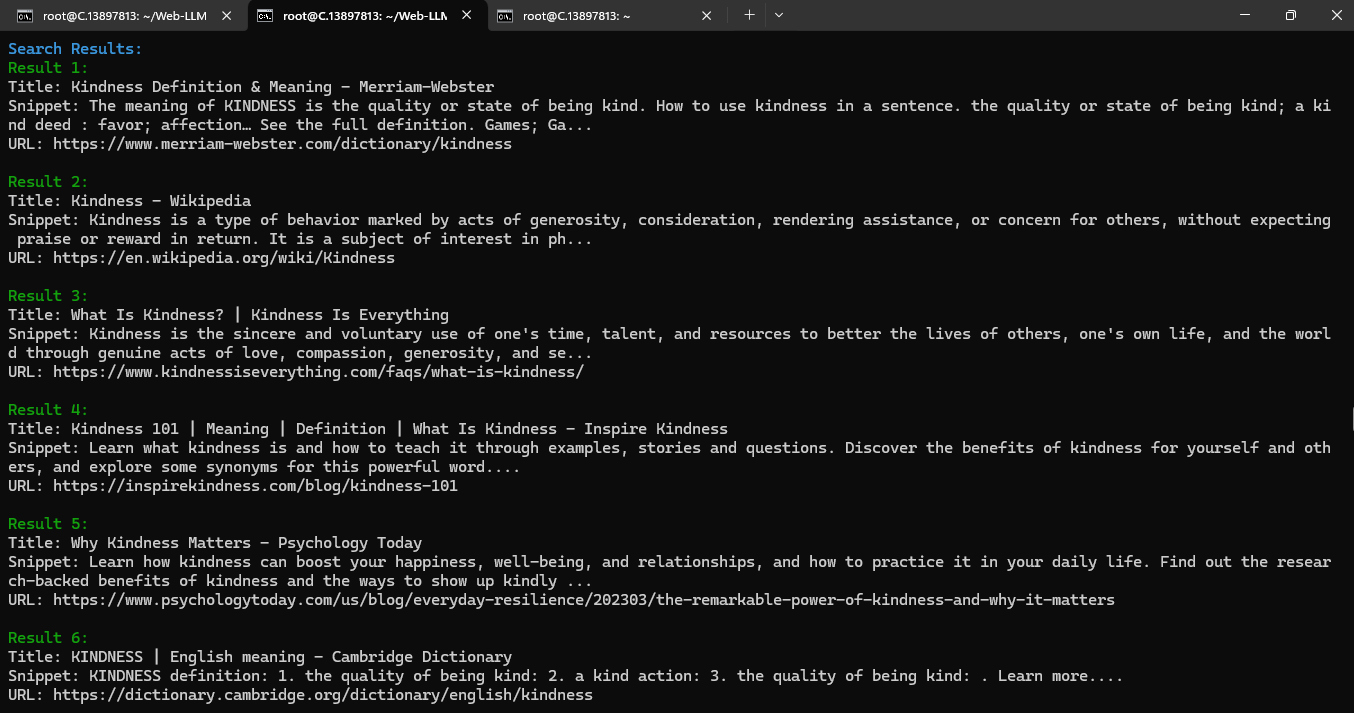
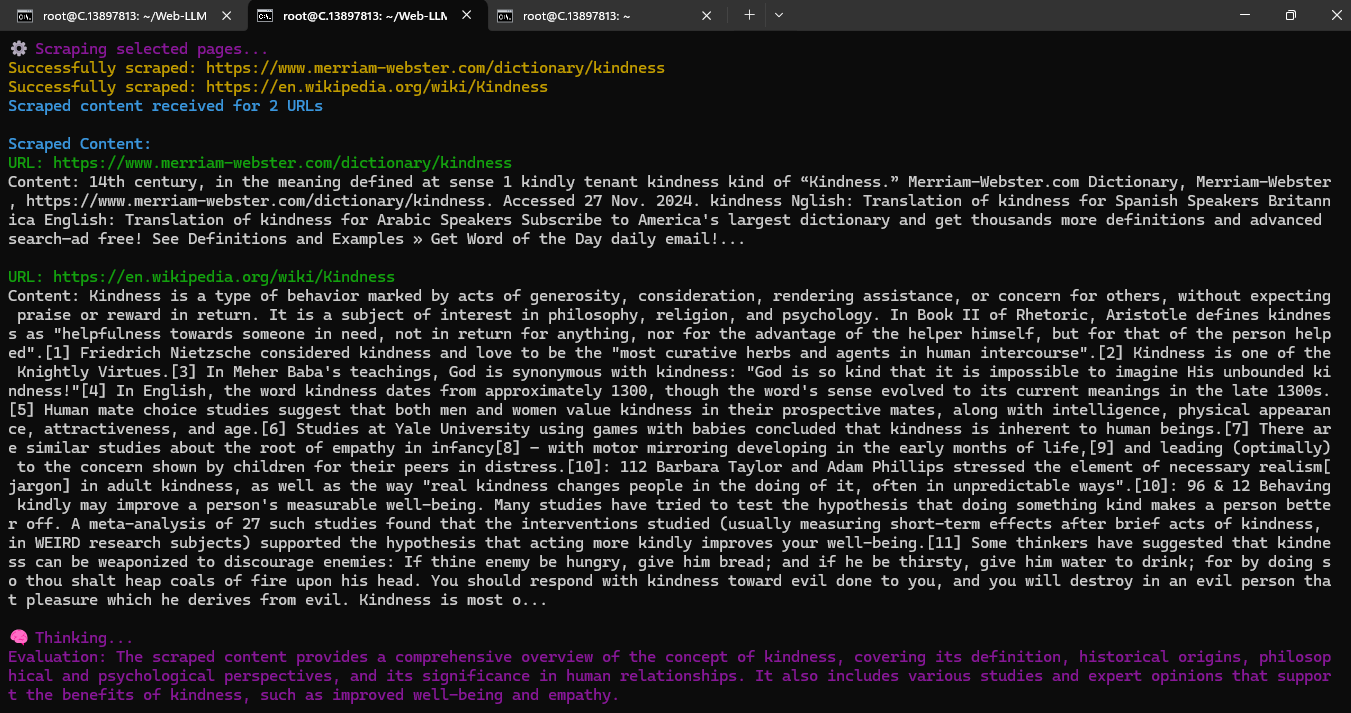
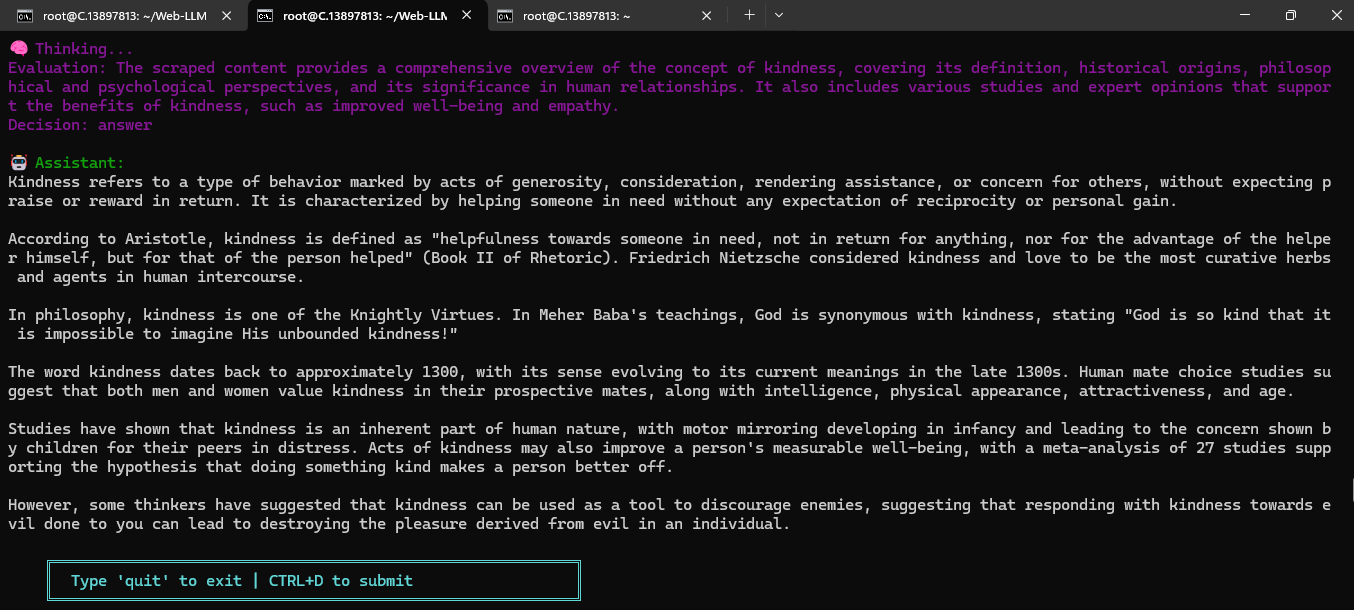
Example 2:
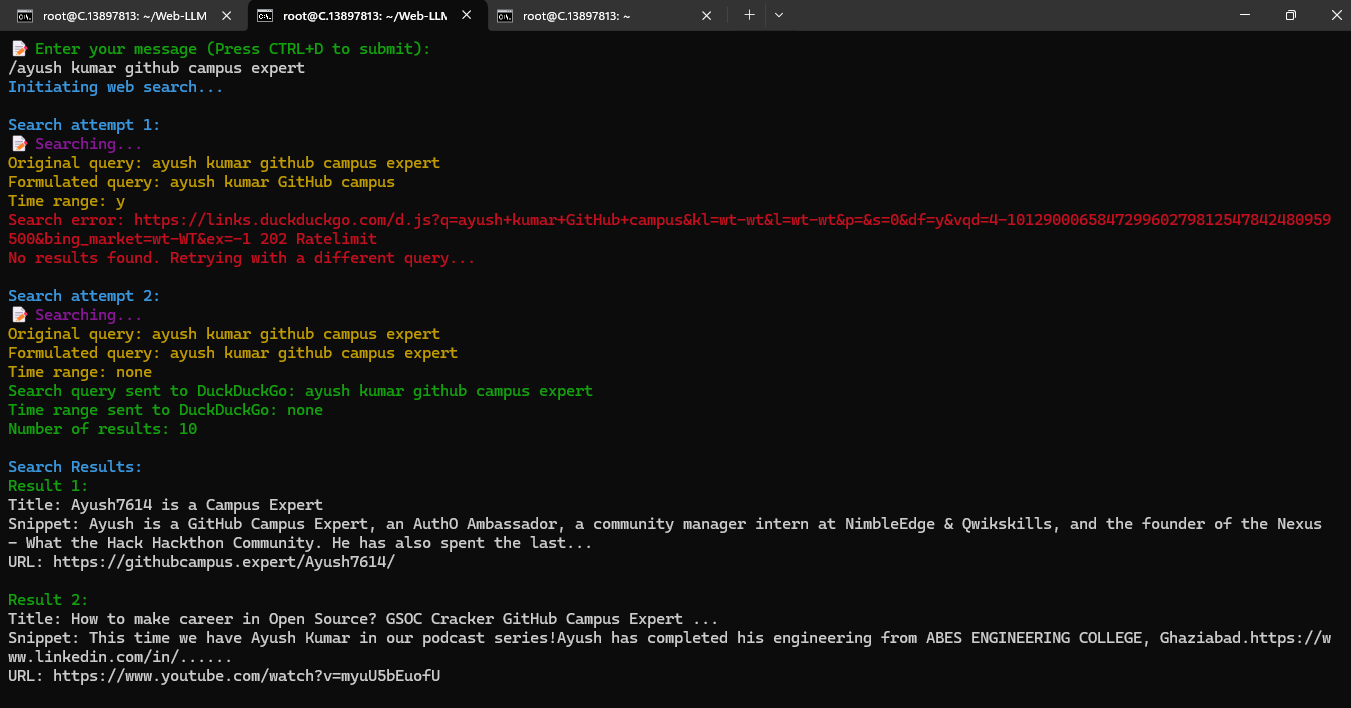
Conclusion
In this guide, we explain the Web-LLM-Assistant-Llamacpp-Ollama open-source python-based web-assisted large language model (LLM) search assistant tool and provide a step-by-step tutorial on installing Web-LLM-Assistant-Llamacpp-Ollama locally on a NodeShift virtual machine. You’ll learn how to install the required software, set up essential tools like vim.



