How to Run Qwen2.5-72B-Instruct Model in the Cloud?


The Qwen2.5-72B-Instruct is the latest large language model from the Qwen Organization. Compared to previous versions of the Qwen Series models, Qwen2.5 is a more robust model that performs exceptionally well in various areas, including coding, mathematics, and instruction-following tasks.
Qwen 2.5 models are released in seven open-source versions: 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B. All models are available under the Apache 2.0 License, except for the 3B and 72B versions, which are available under the Qwen Research and Qwen License.
| Models | Params | Non-Emb Params | Layers | Heads (KV) | Tie Embedding | Context Length | Generation Length | License |
|---|---|---|---|---|---|---|---|---|
| Qwen2.5-0.5B | 0.49B | 0.36B | 24 | 14 / 2 | Yes | 32K | 8K | Apache 2.0 |
| Qwen2.5-1.5B | 1.54B | 1.31B | 28 | 12 / 2 | Yes | 32K | 8K | Apache 2.0 |
| Qwen2.5-3B | 3.09B | 2.77B | 36 | 16 / 2 | Yes | 32K | 8K | Qwen Research |
| Qwen2.5-7B | 7.61B | 6.53B | 28 | 28 / 4 | No | 128K | 8K | Apache 2.0 |
| Qwen2.5-14B | 14.7B | 13.1B | 48 | 40 / 8 | No | 128K | 8K | Apache 2.0 |
| Qwen2.5-32B | 32.5B | 31.0B | 64 | 40 / 8 | No | 128K | 8K | Apache 2.0 |
| Qwen2.5-72B | 72.7B | 70.0B | 80 | 64 / 8 | No | 128K | 8K | Qwen |
The Qwen2.5-72B-Instruct model has a context length of up to 128K tokens and can generate text of up to 8K tokens in length. It demonstrates exceptional performance compared to Llama-3.1-405B in various fields, such as coding and mathematics.
Use cases of Qwen2.5-72B-Instruct Model
There are several use cases of the Qwen2.5-72B-Instruct Model:
- Content Generation: Generate long types of content like blogs, articles, stories, reports, documentation, etc.
- Coding Assistance: Supports code generation, debugging, and automation.
- AI Applications: Facilitates the development of chatbots and virtual assistants.
Qwen2.5-72B-Instruct Performance
| Datasets | Mistral-Large2 Instruct | Llama-3.1-70B-Instruct | Llama-3.1-405B-Instruct | Qwen2-72B-Instruct | Qwen2.5-72B-Instruct |
|---|---|---|---|---|---|
| MMLU-Pro | 69.4 | 66.4 | 73.3 | 64.4 | 71.1 |
| MMLU-redux | 83.0 | 83.0 | 86.2 | 81.6 | 86.8 |
| GPQA | 52.0 | 46.7 | 51.1 | 42.4 | 49.0 |
| MATH | 69.9 | 68.0 | 73.8 | 69.0 | 83.1 |
| GSM8K | 92.7 | 95.1 | 96.8 | 93.2 | 95.8 |
| HumanEval | 92.1 | 80.5 | 89.0 | 86.0 | 86.6 |
| MBPP | 80.0 | 84.2 | 84.5 | 80.2 | 88.2 |
| MultiPL-E | 76.9 | 68.2 | 73.5 | 69.2 | 75.1 |
| LiveCodeBench 2305-2409 | 42.2 | 32.1 | 41.6 | 32.2 | 55.5 |
| LiveBench 0831 | 48.5 | 46.6 | 53.2 | 41.5 | 52.3 |
| IFeval strict-prompt | 64.1 | 83.6 | 86.0 | 77.6 | 84.1 |
| Arena-Hard | 73.1 | 55.7 | 69.3 | 48.1 | 81.2 |
| AlignBench v1.1 | 7.69 | 5.94 | 5.95 | 8.15 | 8.16 |
| MTbench | 8.61 | 8.79 | 9.08 | 9.12 | 9.35 |
Performances on Multilingualism
| Datasets | Qwen2-72B-Instruct | Llama3.1-70B-Instruct | Qwen2.5-32B-Instruct | Mistral-Large-Instruct-2407 (123B) | GPT4o-mini | Qwen2.5-72B-Instruct |
|---|---|---|---|---|---|---|
| Instruction Following | ||||||
| IFEval (multilingual) | 79.69 | 80.47 | 82.68 | 82.69 | 85.03 | 86.98 |
| Knowledge | ||||||
| AMMLU (Arabic) | 68.85 | 70.08 | 70.44 | 69.24 | 69.73 | 72.44 |
| JMMLU (Japanese) | 77.37 | 73.89 | 76.55 | 75.77 | 73.74 | 80.56 |
| KMMLU (Korean) | 57.04 | 53.23 | 60.75 | 56.42 | 56.77 | 61.96 |
| IndoMMLU (Indonesian) | 66.31 | 67.50 | 66.42 | 63.21 | 67.75 | 69.25 |
| TurkishMMLU (Turkish) | 69.22 | 66.89 | 72.41 | 64.78 | 71.19 | 76.12 |
| okapi MMLU (translated) | 77.84 | 76.49 | 77.16 | 78.37 | 73.44 | 79.97 |
| Math Reasoning | ||||||
| MGSM8K (extended) | 82.72 | 73.31 | 87.15 | 89.01 | 87.36 | 88.16 |
| Cultural Nuances | ||||||
| BLEnD | 25.90 | 30.49 | 27.88 | 33.47 | 35.91 | 32.48 |
Model Inputs and Outputs
Inputs
- Text prompt describing the questions, instructions, etc.
Outputs
- The primary output of the Qwen2.5-72B-Instruct model is natural language text in long forms, like code, articles, and stories.
In this blog, you'll learn:
- About Qwen2.5-72B-Instruct Model
- Setup GPU-powered Virtual Machine offered by NodeShift
- Run Qwen2.5-72B-Instruct Model in the NodeShift Cloud.
Step-by-Step Process to Run Qwen2.5-72B-Instruct Model in the Cloud
For the purpose of this tutorial, we will use a GPU-powered Virtual Machine offered by NodeShift; however, you can replicate the same steps with any other cloud provider of your choice. NodeShift provides the most affordable Virtual Machines at a scale that meets GDPR, SOC2, and ISO27001 requirements.
Step 1: Sign Up and Set Up a NodeShift Cloud Account
Visit the NodeShift Platform and create an account. Once you've signed up, log into your account.
Follow the account setup process and provide the necessary details and information.
Step 2: Create a GPU Node (Virtual Machine)
GPU Nodes are NodeShift's GPU Virtual Machines, on-demand resources equipped with diverse GPUs ranging from H100s to A100s. These GPU-powered VMs provide enhanced environmental control, allowing configuration adjustments for GPUs, CPUs, RAM, and Storage based on specific requirements.
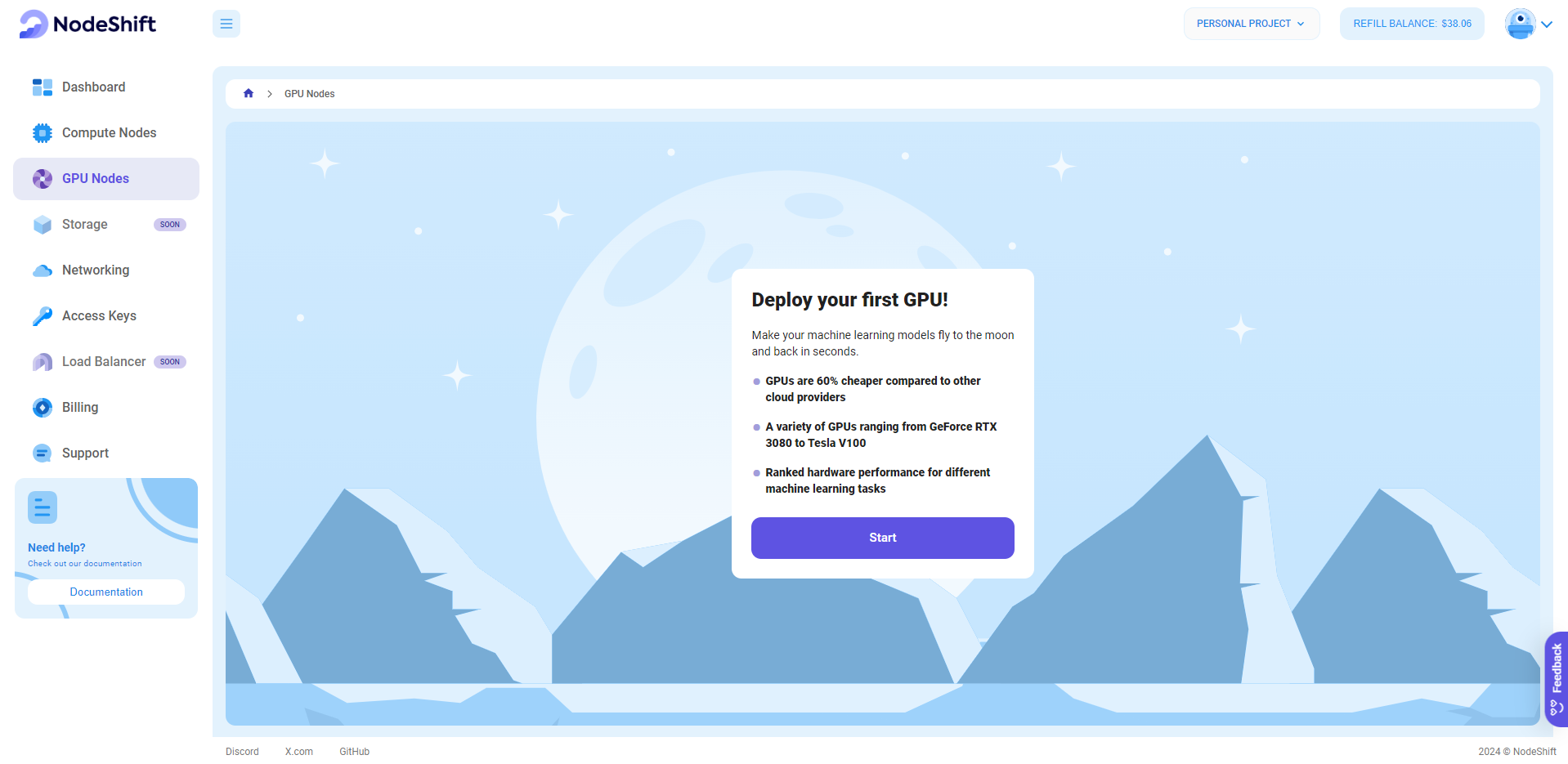
Navigate to the menu on the left side. Select the GPU Nodes option, create a GPU Node in the Dashboard, click the Create GPU Node button, and create your first Virtual Machine deployment.
Step 3: Select a Model, Region, and Storage
In the "GPU Nodes" tab, select a GPU Model and Storage according to your needs and the geographical region where you want to launch your model.
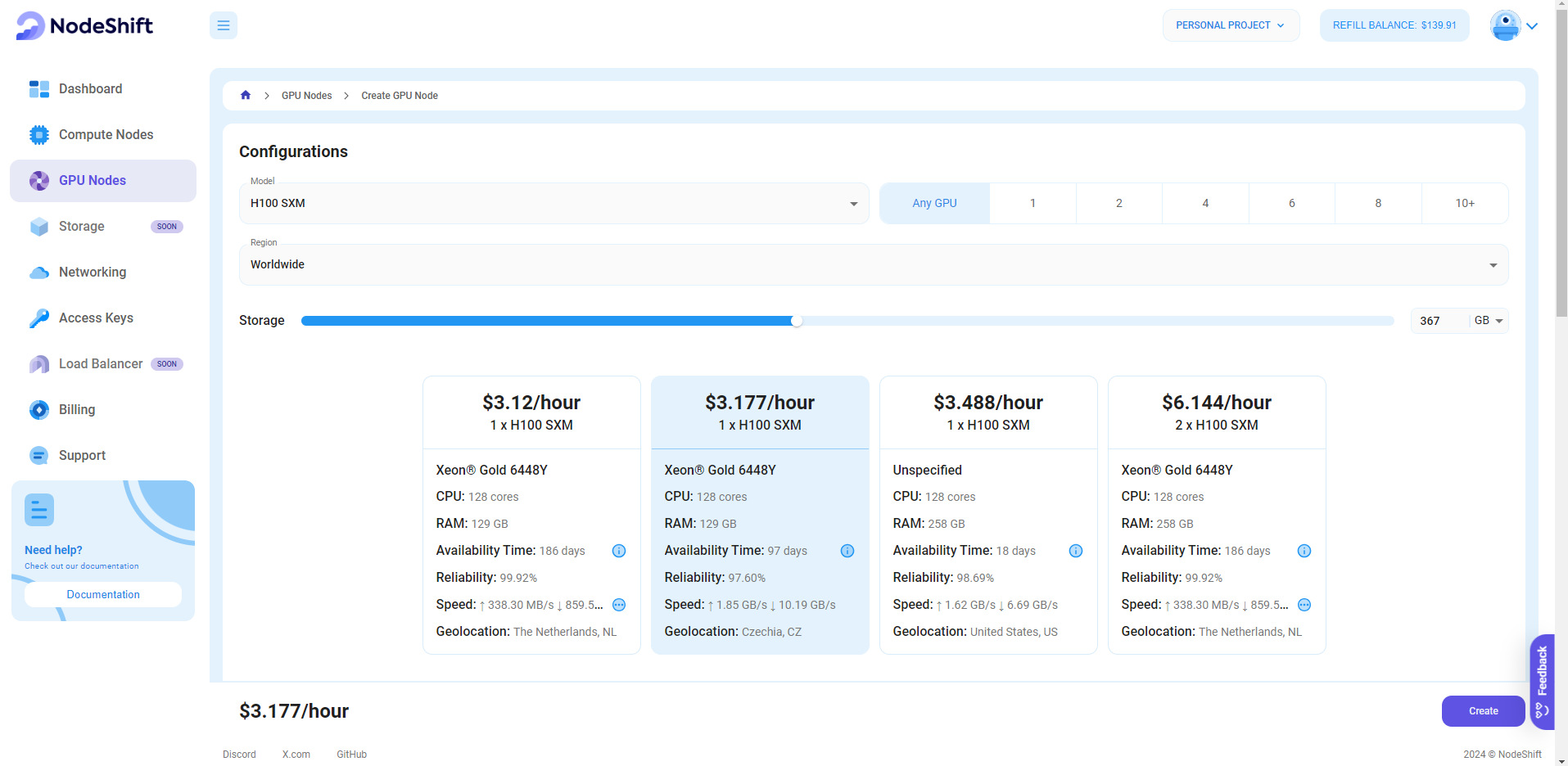
We will use 1x H100 SXM GPU for this tutorial to achieve the fastest performance. However, you can choose a more affordable GPU with less VRAM if that better suits your requirements.
Step 4: Select Authentication Method
There are two authentication methods available: Password and SSH Key. SSH keys are a more secure option. To create them, please refer to our official documentation.

Step 5: Choose an Image
Next, you will need to choose an image for your Virtual Machine. We will deploy Qwen2.5-72B-Instruct on an NVIDIA Cuda Virtual Machine. This proprietary, closed-source parallel computing platform will allow you to install Qwen2.5-72B-Instruct on your GPU Node.
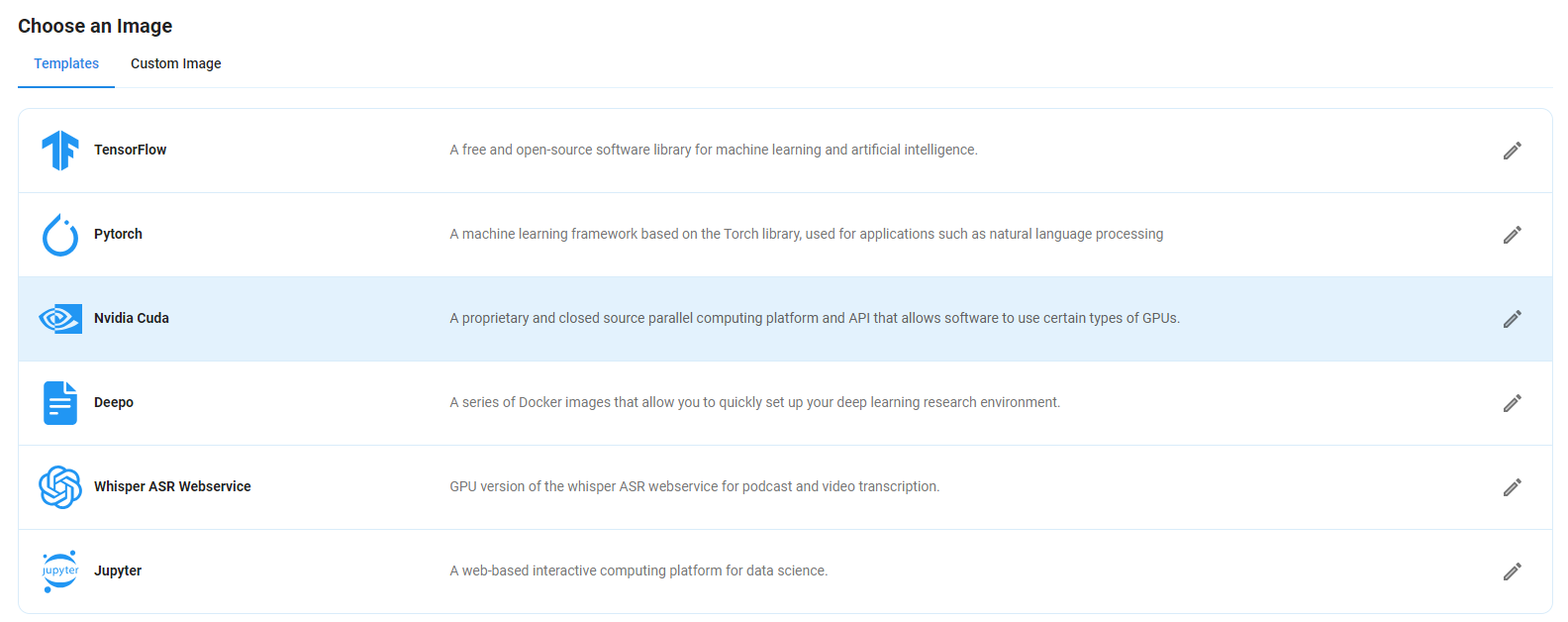
After choosing the image, click the 'Create' button, and your Virtual Machine will be deployed.
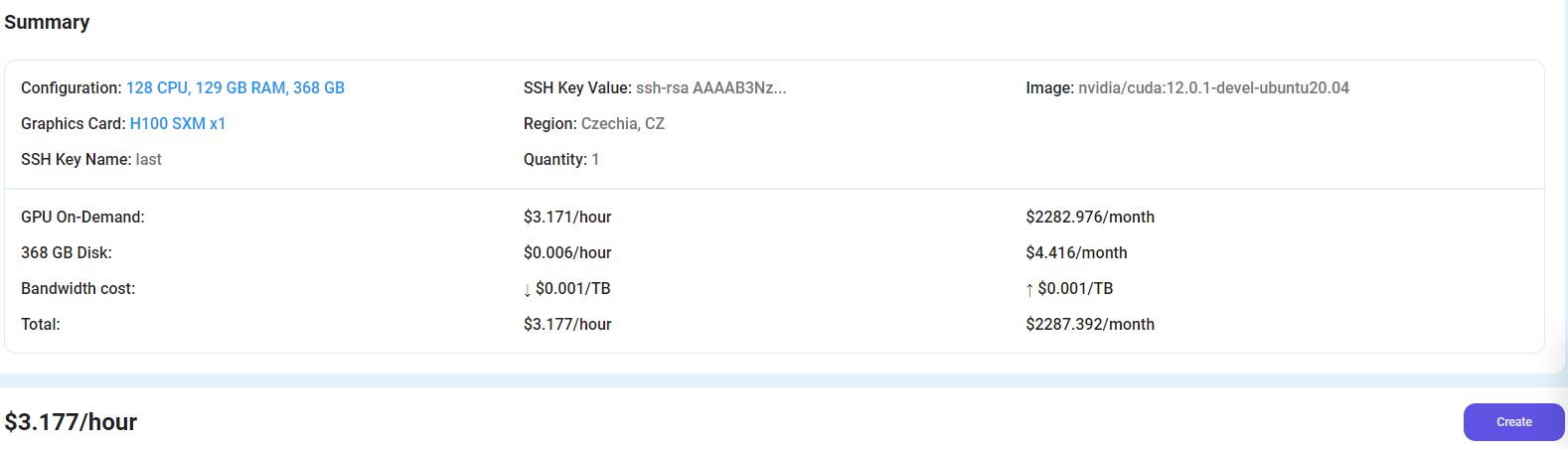
Step 6: Virtual Machine Successfully Deployed
You will get visual confirmation that your node is up and running.
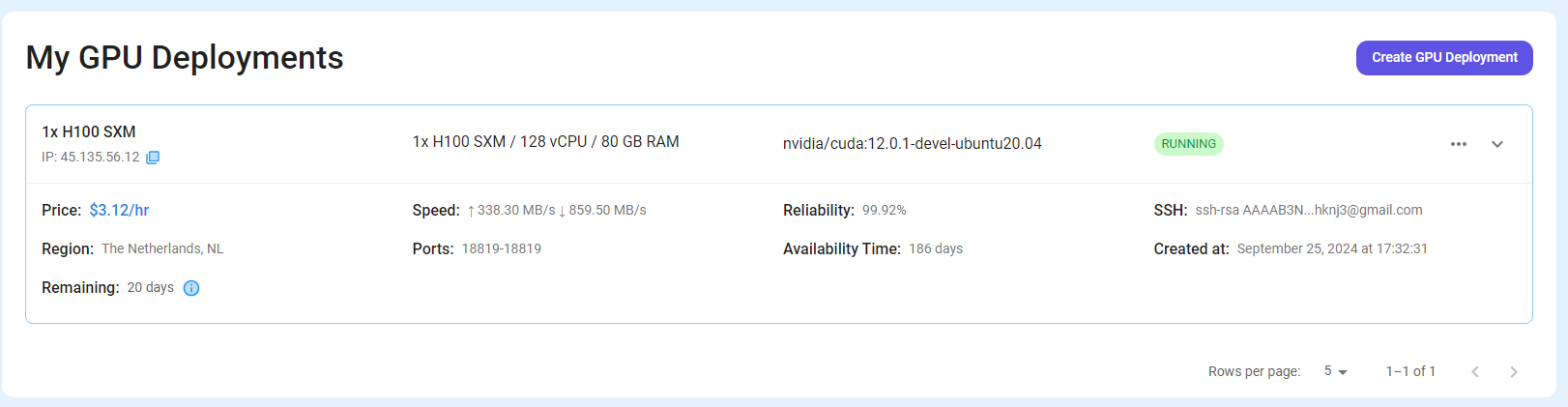
Step 7: Connect to GPUs using SSH
NodeShift GPUs can be connected to and controlled through a terminal using the SSH key provided during GPU creation.
Once your GPU Node deployment is successfully created and has reached the 'RUNNING' status, you can navigate to the page of your GPU Deployment Instance. Then, click the 'Connect' button in the top right corner.
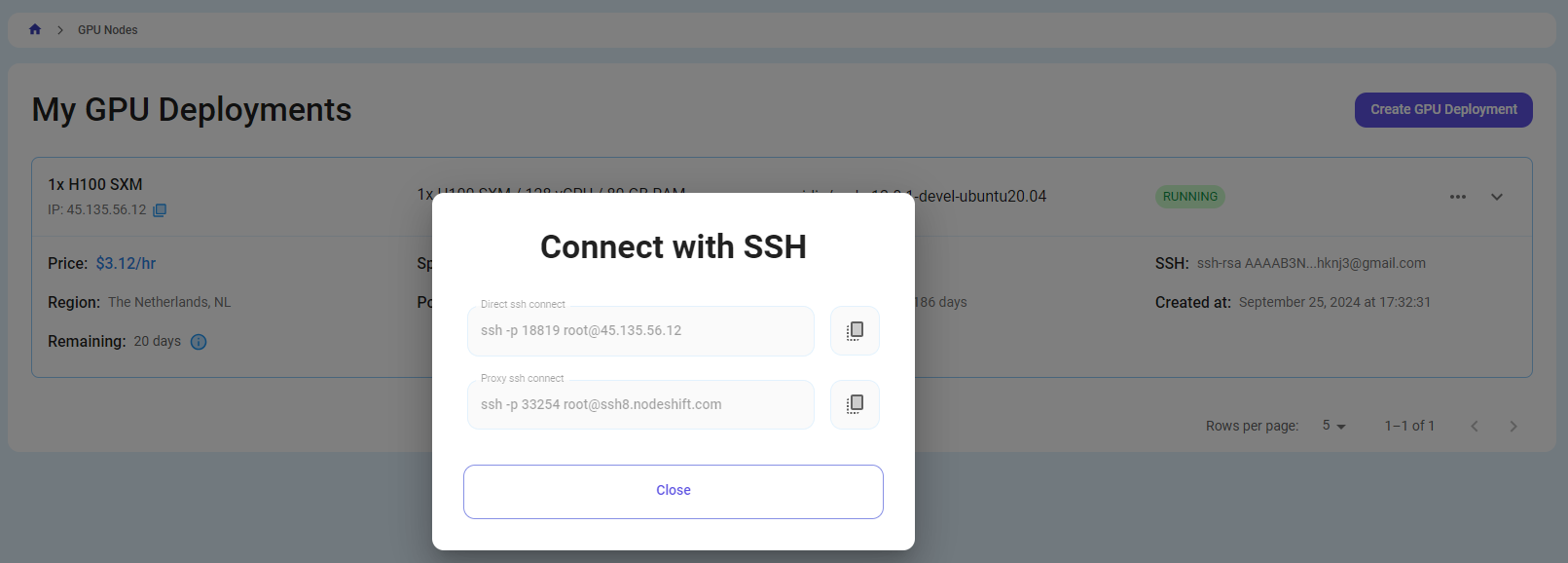
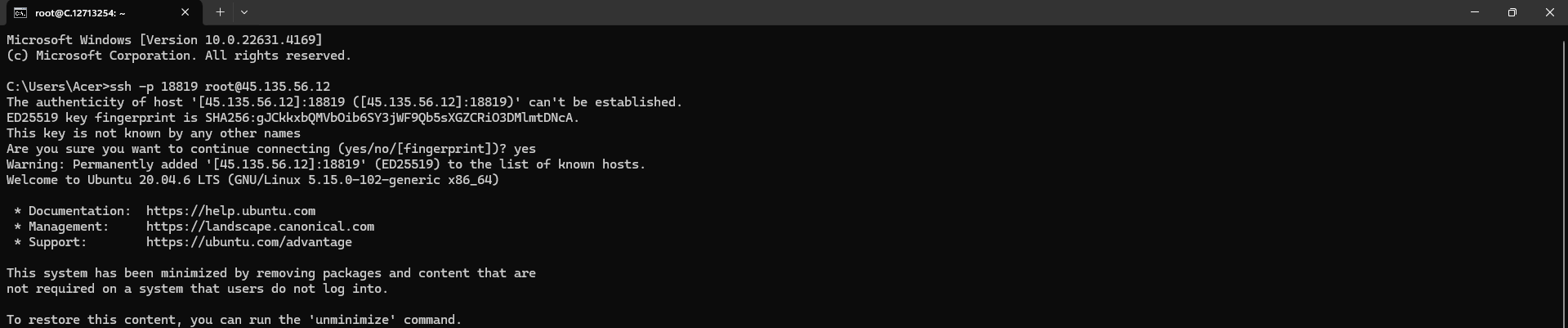
Now open your terminal and paste the proxy SSH IP or direct SSH IP.
Next, If you want to check the GPU details, run the command below:
nvidia-smi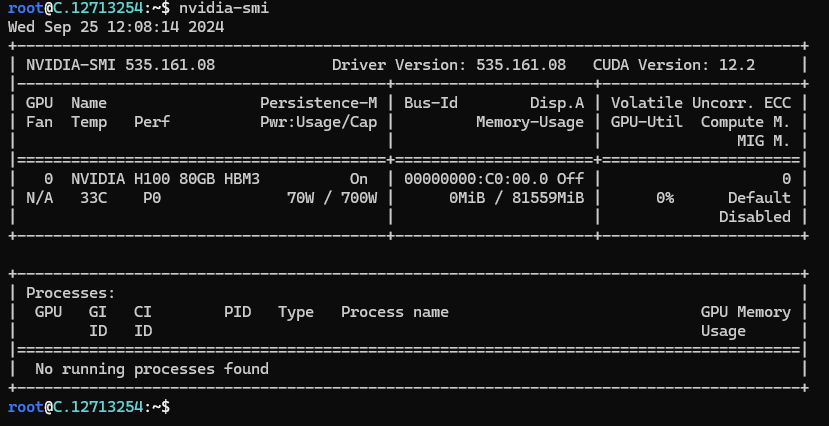
Step 8: Install Qwen2.5-72B-Instruct
After completing the steps above, it's time to download Qwen2.5 from the Ollama website.
Website Link: https://ollama.com/library/qwen2.5:72b
We will be running Qwen2.5-72B-Instruct. Select the 72B model from the website.
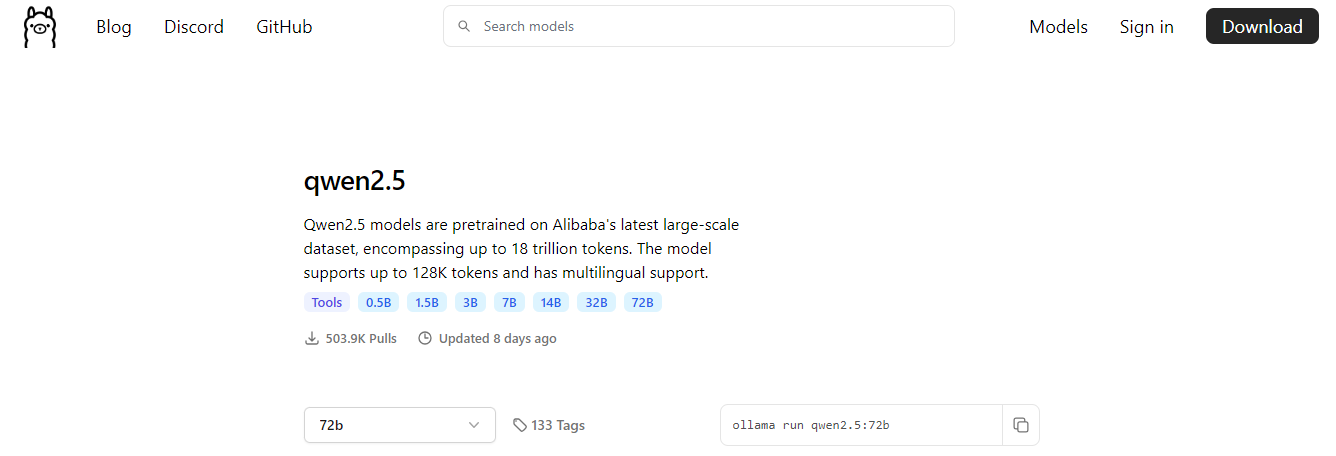
Then run the following command to install Ollama:
curl -fsSL https://ollama.com/install.sh | sh
After the installation process is complete, run the following command to see a list of available commands:
ollama
Next, run the following command to host the Qwen2.5 model so it can be accessed and utilized efficiently.
ollama serve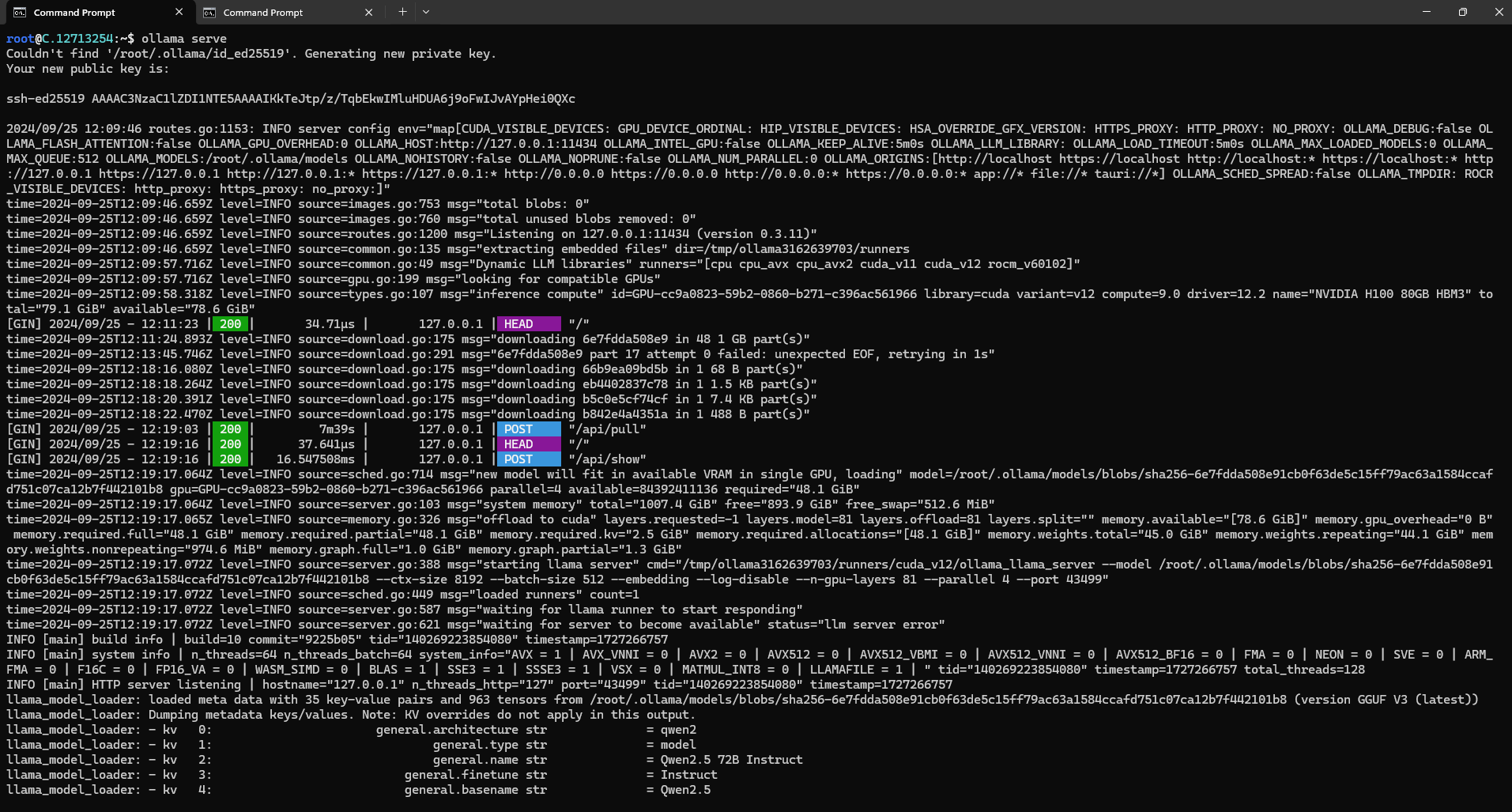
Step 9: Pull Qwen2.5-72B-Instruct Model
To pull the Qwen2.5-72B-Instruct Model, run the following commands:
ollama pull qwen2.5:72b

Step 10: Run Qwen2.5-72B-Instruct Model
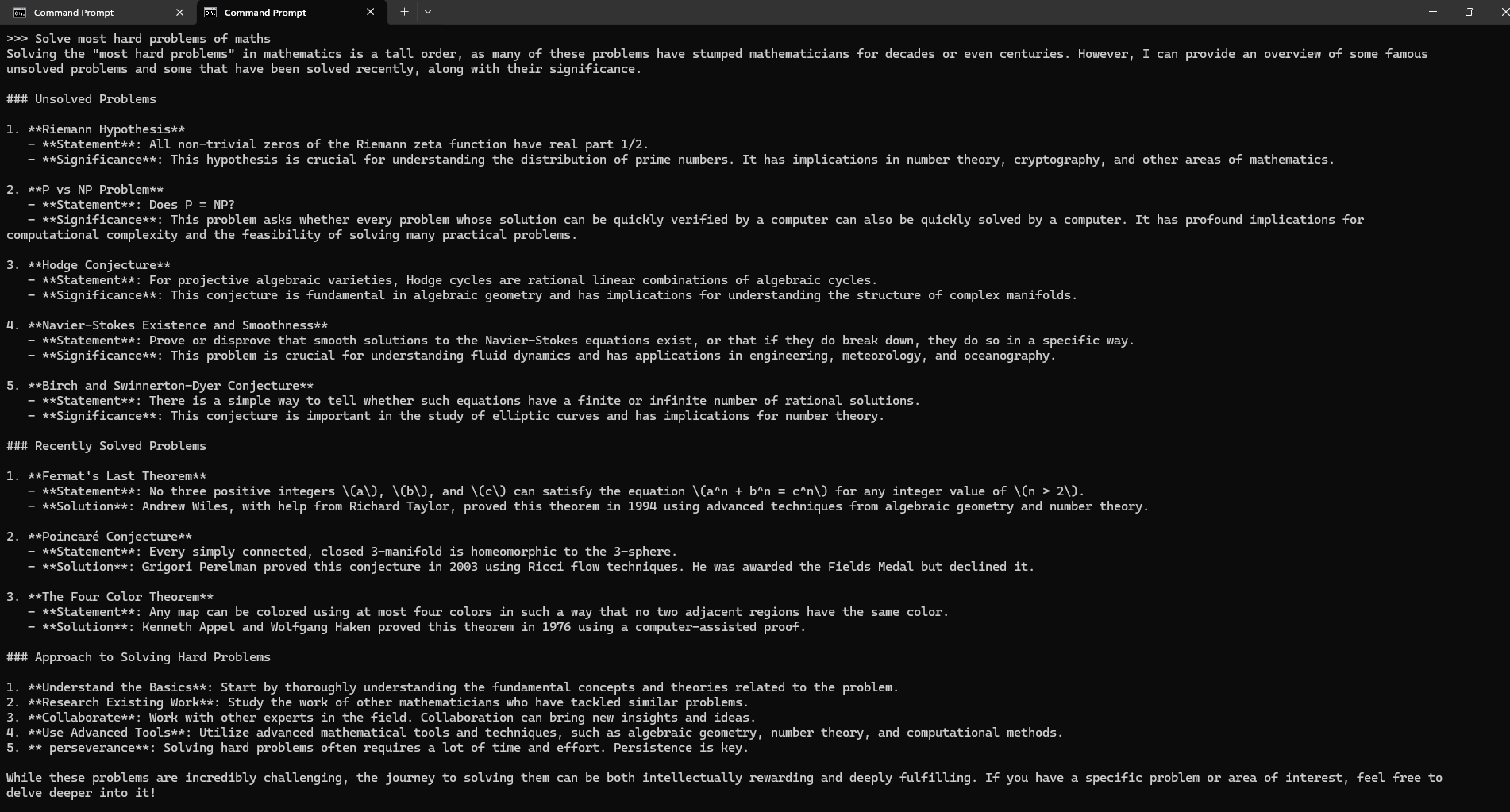
Now, you can run the model in the terminal using the following command and interact with your model:
ollama run qwen2.5:72b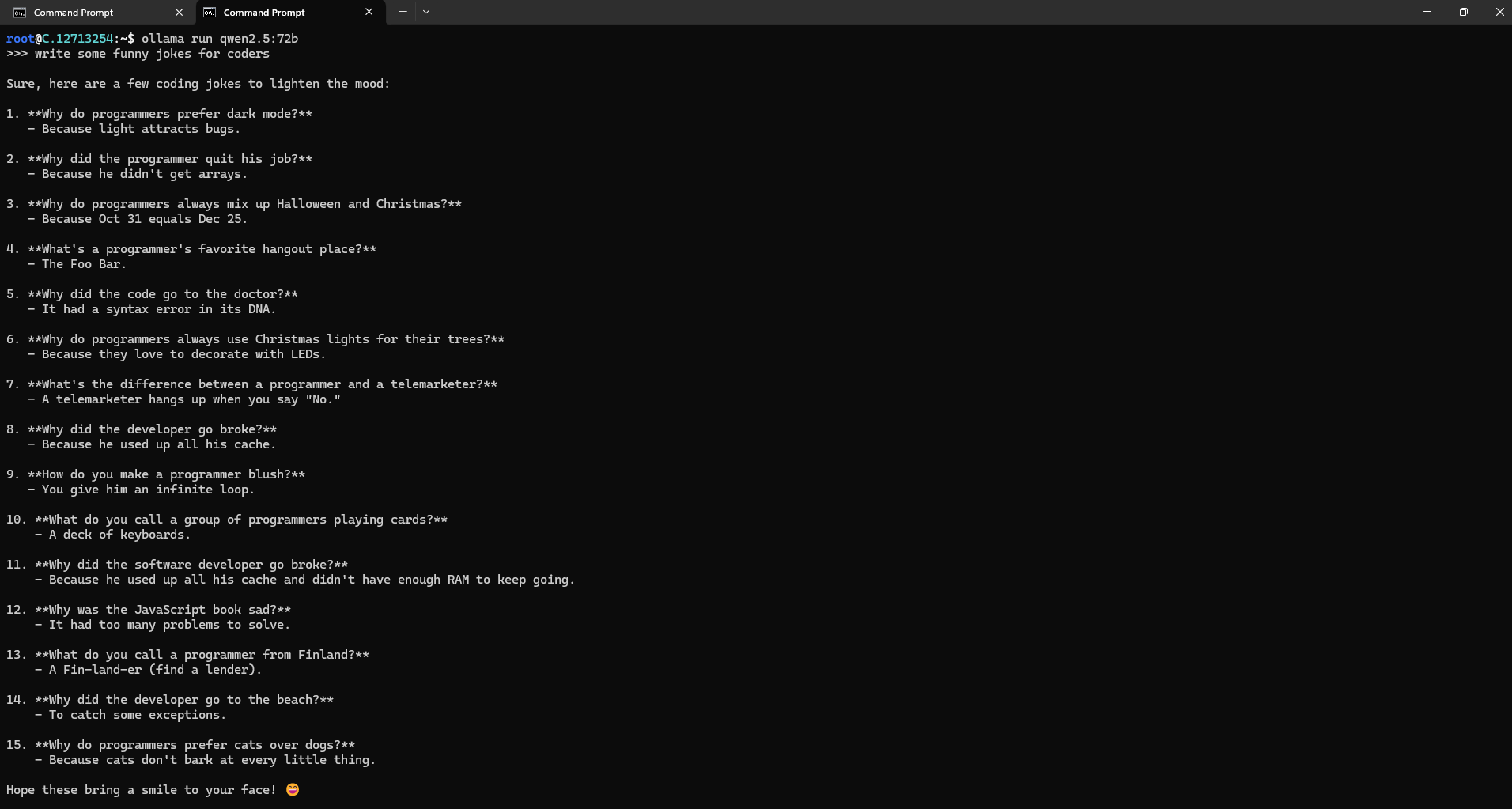
Conclusion
In this guide, we've walked through setting up and running the Qwen2.5-72B-Instruct model Locally on a GPU-powered virtual machine. With Qwen2.5-72B-Instruct, you now have the tools to generate anything like text, code, and maths from prompts. By following these steps, you have the power of advanced AI text generation while enjoying the flexibility and efficiency that Qwen2.5-72B-Instruct offers.
For more information about NodeShift:



